
機械学習エンジニアやデータサイエンティストが、一番最初に行う作業をご存知でしょうか?会社や組織から課題を与えられた場合、最初に行うのが「探索的データ解析」と呼ばれる作業です。
探索的データ解析、英語ではExplanatory Data Analysis(略してEDA)とは、データの特徴を探求し、構造を理解することを目的としたデータサイエンスの最初の一歩です。
探索的データ解析は機械学習のタスクの一番最初のフェーズで、まずはデータに触れてみて、データを視覚化したり、データのパターンを探したり、特徴量やターゲットの関係性/相関性を感じるとるのが目的です。
より高度な機械学習のモデルの構築をしたり、難解な問題を解決する際には、特徴量エンジニアリング(英語でFeature Engineering)を必要することが多々あり、その際に深いデータの知識と理解が求められます。
問題を解決する前に、どのようなデータセットを扱っているのか、どのような状況にあるのかを、しっかりと理解するのが重要であり、「探索的データ解析(EDA)」はまさしくそれを目的とした作業となります。
今回のチュートリアルでは、データサイエンティスト入門として、探索的データ解析で頻繁に使われる基本的な関数などをご紹介させていただきます。利用するデータセットは、機械学習入門者であれば一度は目にしたことある「アヤメ(Iris Dataset)」のデータセットを使いましょう。

Irisは日本語でアヤメをさします。こちらの花です。
この記事の目次 [隠す]
なぜ探索的データ解析が重要なのか?
データサイエンティストの仕事の多くは、当然ながら、何かしらのデータを使って行うことが多いわけです。長い間、親しんで使ったデータもあれば、全く見たことも触ったこともないデータも当然あります。
これらのデータに対して「仮説」を立てて、最終的に予測モデルを構築するのですが、そのプロセスにおいて「探索的データ解析」は重要な役割を持っています。
有名なドイツの哲学者「アルトゥル・ショーペンハウアー氏」の引用ですが、「金を探し求めている錬金術師達は、金よりも価値の高い多くのものを発見しました(意訳)」と残していますが、まさに探索的データ解析はデータサイエンティストにとって、データをより深く理解して「データよりも価値の高いもの」を見つけるための作業なのです。

ドイツの著名な哲学者 アルトゥル・ショーペンハウアー氏
探索的データ解析で使うツールとは?
データ解析で使うツールですが、様々なツールが出回っていますが、本チュートリアルでは世界的にも標準的なPythonのライブラリである「Pandas(パンダス)」「Matplotlib(マットプロットリブ)」「NumPy(ナンパイ)」を使ってEDAを進めていきたいと思います。
簡単ではありますが、この基本的な3つのライブラリについて見ていきましょう。
Pandasとは?
![]()
Pandas(読み方はパンダまたはパンダス)とは、オープンソースのPythonのライブラリです。機械学習エンジニアの中でも非常に人気が高く、大量なデータを高速かつ簡単に扱うのに優れているツールです。Pandasを使ったことがない方は、Pandas入門コース(無料)を是非ご参考ください。
matplotlibとは?
![]()
Matplotlib(読み方はマットプロットリブ)とは、同じく機械学習では頻繁に登場する、グラフを作成するオープンソースのライブラリです。今回の探索的データ解析でもグラフを多数使いますが、機械学習の作業においてグラフは非常に重要なツールです。ヒストグラムや散布図、その他にも様々な複雑なグラフがとても簡単に作成することが可能です。(参照:Maplotlib入門コース(無料))
NumPyとは?
![]()
機械学習界の大御所「Numpy(読み方ナンパイ)」です。こちらもオープンソースのPythonライブラリとなります。機械学習では複雑かつ膨大な線形代数の処理をすることが多数あり、そのような処理を、高速かつ効率的に行ってくれるツールです。
codexa(コデクサ)では、Numpyの入門コース、さらに機械学習のための線形代数コースを無料で公開しています。より詳しく使い方をマスターしたい方は、是非こちらのコースの受講をご検討ください。
今回利用するアヤメのデータセットについて
さて、今回の探索的データ解析の練習で使うデータセットですが、「Iris Dataset」を利用します。Kaggleにて無料会員登録後に、下記のURLからダウロードが可能です。(参照:Kaggleについて)
https://www.kaggle.com/uciml/iris
アヤメのデータセットですが、元々はフィッシャー氏の1936年の論文「The Use of Multiple Measurements in Taxonomix Problems」で提示されたデータセットで、機械学習の初心者が分類問題を練習する際に広く使われる、とても有名なデータセットです。
このデータセットの特徴量(説明変数)は、下記の4つの項目が含まれています。
- Sepal Length – がく片の長さ(cm)
- Sepal Width – がく片の幅(cm)
- Petal Length – 花弁の長さ(cm)
- Petal Width – 花弁の幅(cm)
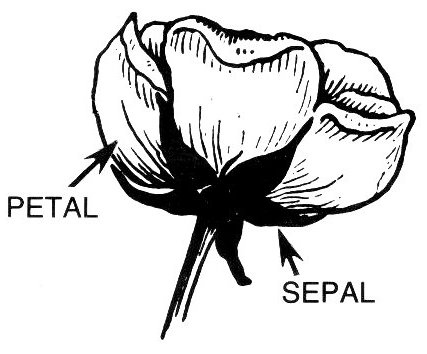
アヤメには下記の3つの種類があり、上記の4つの特徴量は、どの種類のアヤメに属するかを分類予測するために使われます。
- Iris-Setosa(アイリスセトサ)
- Iris-Versicolor(アイリスバージカラー)
- Iris-Virginica(アイリスバージニカ)
データセットには上記の3種類のアヤメ毎に50の観測データが含まれています。つまり全体で150の観測データが含まれているデータセットです。
探索的データ解析チュートリアル
このデータセットを使ってデータ解析の初歩的な流れを、Pythonとライブラリを使いながらやってみましょう。本チュートリアルですが、Python 3.xを使っています。Python 2.xをお使いの方は、動かないコードがある可能性がありますので、Python 3.xへアップデートをお願いします。
また本チュートリアルはJupyter Notebookを利用しています。こちらは必須ではありませんが、コードの編集が非常に簡単になります。まだ環境構築をされていない方は、こちらをご参考にインストールをお勧めいたします。(必須ではありませんので、Python3.xが動く環境であれば問題ありません)
必要ライブリーのインポート
まずはPandas、Matplotlib、numpyの3つのライブラリのインポートをしましょう。 import関数 は必要なライブラリを読み込み、使えるようにしてくれます。また import に as と指定することで、そのライブラリを省略して呼び出すことが可能です。
データセットをデータフレームとしてインポート
SQLやエクセル、CSVなどのファイルをPythonへ読み込む方法は多数ありますが、今回はpandasの read_csv という関数を使ってみましょう。 read_csv ですが、その名の通りで主にCSVファイルを読み込む際に利用します。
下記のコードで、CSVファイルを読み込み、さらにpandasのデータフレーム形式へ変換します。「Iris.csv」のファイルの格納先が、Jupyter Notebook/Pythonの立ち上げのディレクトリと異なる場合は、下記の’Iris.csv’にディレクトリの指定もしてあげましょう。(同じディレクトリの場合は追記なしで問題ありません)
基本的なデータ探索
まずは、最も基本的なデータ探索を行ってみましょう。基本的と言えど、データサイエンティストが初見のデータを扱うときは、ほとんどのケースで同様の確認を行います。
まずは head() を使って、データフレームの最初の5行を表示させてあげましょう。下の図のようにIrisのデータフレームの最初の5行が出力されるはずです。まずはデータフレームの最初の5行を表示させることで、このデータに何がどのように含まれているのかを、ざっくりと確認します。
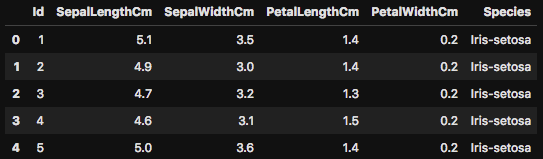
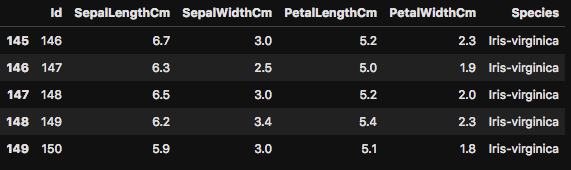
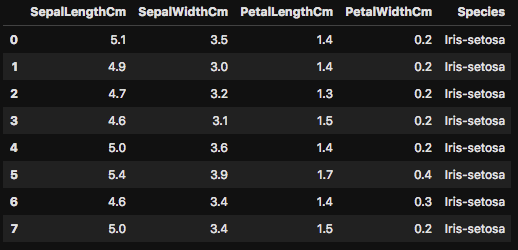
このhead()ですが、さらに数字を関数に入力することで、表示する行数も簡単に変更が可能です。5行だけだと、よくデータが分からないときは、行数を増やして確認をしてみましょう。
describe()ですが、データセットの分散を非常に簡単かつ素早く確認をすることが可能です。口で説明するよりも、まずは実際に実行してみましょう。
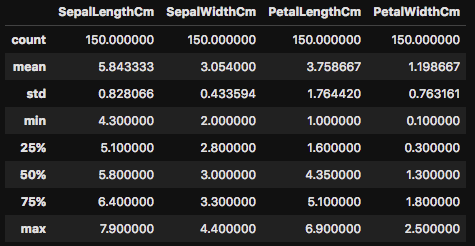
このように、この関数を使うことで、データフレームのcount(データ数)やmean(平均)、さらにはstd(標準偏差)などを一発で確認をすることが可能です。(参照:標準偏差やMeanなどに不安がある方は統計入門コースをご参照ください)
また、データの分散を示す「min(最小値)」「25%〜75%」「max(最大値)」の確認も可能です。 describe() を使うことで、このデータがどのような分散をしているのかを確認できます。このようにデータの分散状況を確認して、場合によってはさらに詳細を調べていき、必要に応じて値の削除や代用など、データクレンジング(データを掃除する)したりします。
先述しましたが、このアヤメのデータセットでは上図のように4つの特徴量が与えらており、これらを学習して3種類のアヤメのどれに属するかを分類予測したい訳です。
となれば、やはり気になるのは、この特徴量とアヤメの各種類との関係性です。例えば、Iris-Setosa(アヤメの1種類)のがく片と花弁の長さに何か特徴はあるのか?などをデータをみて直感的に把握したいですよね。
では、実際にそのコードを書いてみましょう。

このように groupby を使うことで、とても簡単にデータを要約することが可能です。
ではアヤメの種類と特徴量の関係で何か特筆すべき特徴は見つかったでしょうか?上図は小さいので見辛いかもしれませんが、データを確認してみるとPetalLengthCM(花弁の長さ)を比較してみるとIris-Setosaの最小-最大値は1.0〜1.9cmなのに対して、Iris-versicolorの最小-最大値は3.0-5.1cmと大きく異なっているのが分かります。
機械学習でモデルフィッティングをする前でも、このように二つの種類のアヤメの花弁の長さには明確な違いがあるのがわかる訳です。
次は info() を使ってみましょう。この関数は、データフレーム全体の情報を要約して表示してくれます。
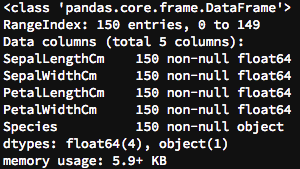
このように、データフレームのカラム数や行数、さらには各カラムのデータタイプなどの情報が表示されます。新しいファイルを読み込んだ際は、 info() を使ってデータフレームの全体を一目で把握することが可能です。
カラムの値を確認する
次に unique() と value_counts() を使っていきましょう。この2つの関数も初期のデータ探索でよく使われます。
array([‘Iris-setosa’, ‘Iris-versicolor’, ‘Iris-virginica’], dtype=object)
上記の unique() のコードを動かしてみると解りやすいかと思いますが、このようにデータフレーム内のユニークな値のみを出力してくれます。今回は Species のカラムを指定したところ、先述した通り3種類のアヤメの種類がユニークな値として出てきました。
これは事前のデータの情報で知っていたことではありますが、実際にデータでそれを確認するのは重要な作業です。稀に聞いていた話と異なるデータが含まれる場合もあり、そのまま学習モデルの構築を進めるとドツボにハマるなんてことも・・(汗)
さて、次はvalue_counts()をやってみましょう。この関数はカラム内のデータのカウント数をまとめてくれます。実際に例をみた方が解りやすいかと思います。
Iris-setosa 50
Iris-versicolor 50
Iris-virginica 50
Name: Species, dtype: int64
このようにSpeciesのカラムの各データをまとめて、テーブルを作成してくれます。これも冒頭のデータ説明の際に触れましたが、各種別に50個ずつのデータが入っていることが確認できますね。
データが小規模の場合は、確認するもの簡単な作業ではありますが、機械学習では100万、1000万と非常に規模のでかいデータを扱いますので、一手間でもデータを理解するという意味で、このような確認作業を行なった方が良いでしょう。
カラムをデータフレームから削除する
機械学習では頻繁に発生しますが、データセットの中から使うデータと使わないデータを判別して処理をしなくていけません。次は drop() を使って、実際にデータフレームから Id のカラムを削除してみましょう。
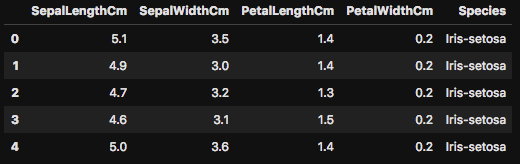
念のため head() で最初の5行を表示してみましたが、ご覧の通り Id のカラムが削除されているのが確認できます。
データの可視化
さて、ここからはデータの可視化をMatplotlibを使ってやってみましょう。上記のようにデータのテーブルを確認するのも重要ですが、グラフなどに可視化することで分かることも多々あります。実際に機械学習エンジニアの作業として、このようにデータをグラフ化して、そこから内容を紐解いていく作業も含まれます。
ヒストグラム
最初の可視化はヒストグラムを作ってみましょう。ヒストグラムは、データーの散らばり具合(分散)を把握するのに約立つグラフです。Matplotlibの hist() を使うと非常に簡単にヒストグラムを作成することが可能です。
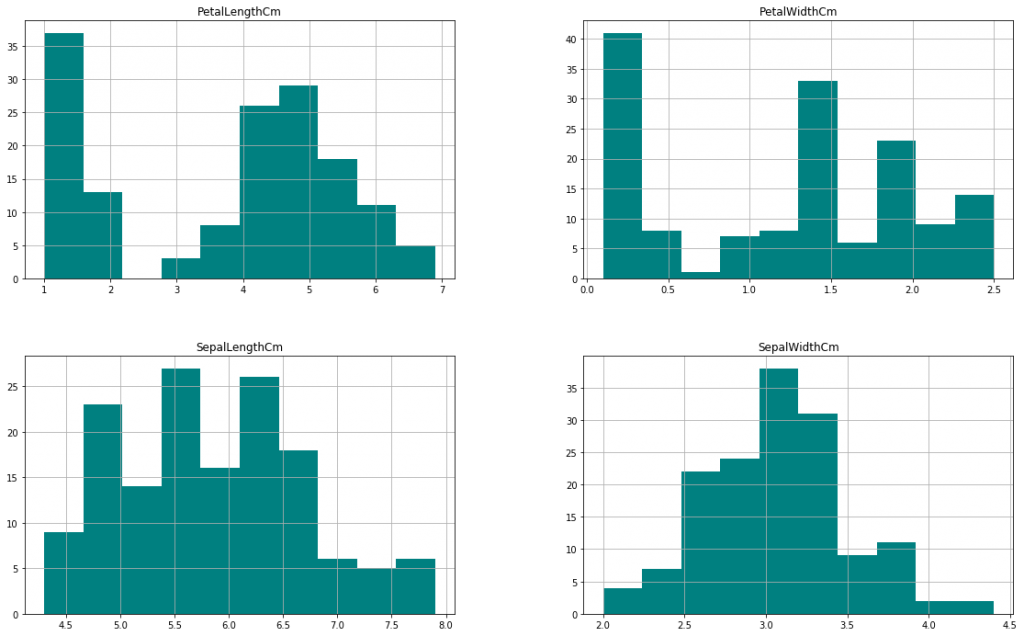
上記のように各カラムのデータの分散を一目で把握することが可能です。例えばがく片の幅と長さですが、山が二つあるように見えますよね(Bimodal Curv -二項曲線)。データの数字だけをみていても解りにくいことが、このようにグラフを作ることで一目で把握できることもあります。
ヒストグラムなどの詳細は、機械学習のための統計入門コース(前編)にてカバーしています。不安がある方は、コースの受講をご検討ください!
特徴量ごとに重ねたヒストグラムを作って確認
上のヒストグラムですが、各カラムごとのヒストグラムでしたが、今度はよりデータの解析がしやすい形のヒストグラムを生成してみましょう。
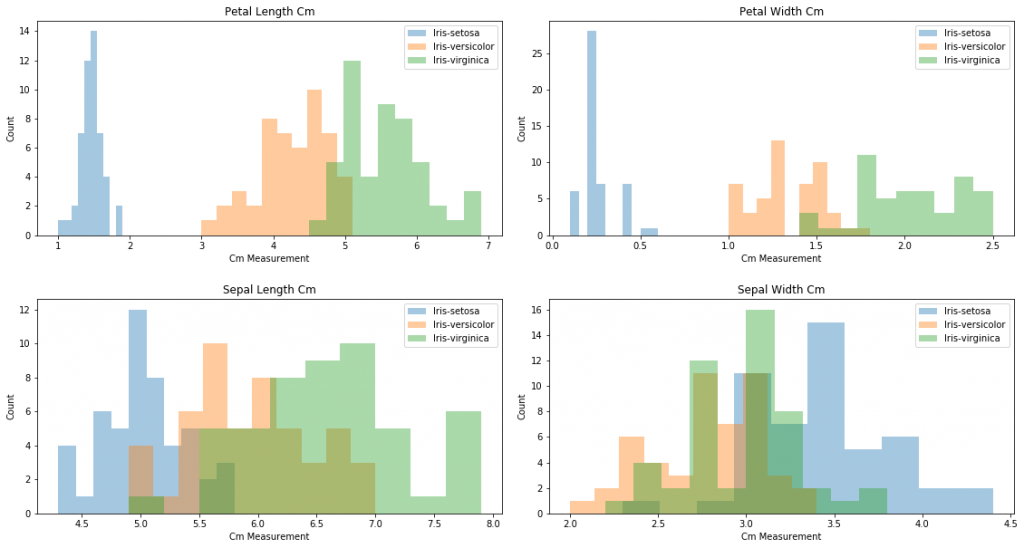
ちゃんとグラフは描写されましたでしょうか?こちらですが、、コードを見ていただくと解りやすいかと思いますが、今度は各特徴量(がく片と花弁の長さ&幅)をターゲットクラス(3種類のアヤメの種類)毎に分けて、重ねて表示させたヒストグラムとなります。
例えば、左端のPetalLengthCm(萼片の長さ)のグラフを見てみると、人間の目で見てもかなり明確に種別を判別できる傾向が出ているかと思います。グラフを作成するのは、時間がかかる作業ではありますが、このように後々、非常に役に立つ情報が見つかる可能性もありますので、手間ではありますが、初めて触るデータは時間をとってしっかりと可視化をしていきましょう。
散布図(スキャタープロット)
次は散布図を描写して見ましょう。先ほどのヒストグラムは一つの特徴量のデータの分布(散らばり具合)を確認するためのものでしたが、散布図では2つの特徴量の相関関係を可視化することが可能です。
では早速コードを実行して見ましょう。
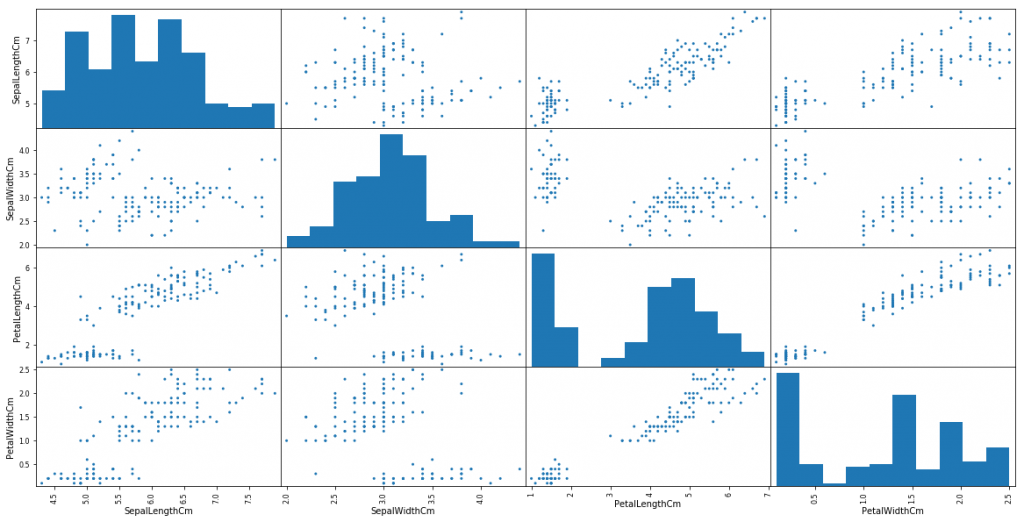
たった一行のコードで、このように各特徴量も散布図のマトリックス(行列)が作成できてしまいます。Matplotlibがデータサイエンティストの人気のツールの理由が解りますね。
ヒストグラムは先ほど出した通りですが、今度は2つの特徴量での散布図が出ています。例えば、4段目の右から数えて3つ目の散布図を見てみましょう。こちらは、X軸が萼片の長さでY軸が萼片の幅の散布図です。当然といえば当然ですが、長さが大きくなればなるほど、幅も大きくなっているのが確認できます。散布図をみることで、この2つの特徴量には「強い正の線形関係」があることが把握できます。
データフレームのフィルタリング
次のセクションでは、様々な方法を使ってデータフレームのフィルタリングをやってみましょう。フィルタリングですが初歩的ではありますが、非常に重要かつパワフルなツールです。
データサイエンスの世界では、頻繁にデータテーブルにフィルターをかけて、ある特定の事柄について詳しくみていく作業が発生します。例えば、会社の全期間の売り上げデータの中から、毎年の三月のみ比較して分析するなどを考えてみると想像しやすいですよね。
では、実際にIrisのデータフレームを実例としてフィルタリングをやってみましょう。
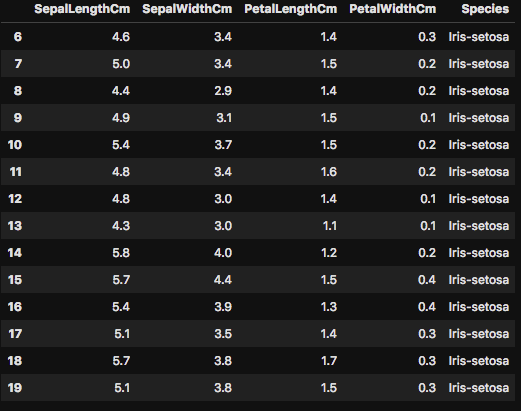
上記のコードでは、データフレームの行インデックスが6-20までのフィルタリングとなります。しっかりと、嬢のイメージのようなテーブルが出力されましたか?
次は少し応用編をやってみましょう。
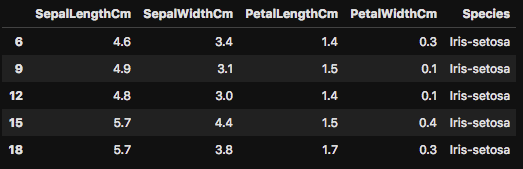
今度は行インデックス6-20のレンジ内で3等間隔にデータをフィルターしてみました。
次はアヤメの種類が「Iris-setosa」で最初の10行のデータを表示させてみましょう。
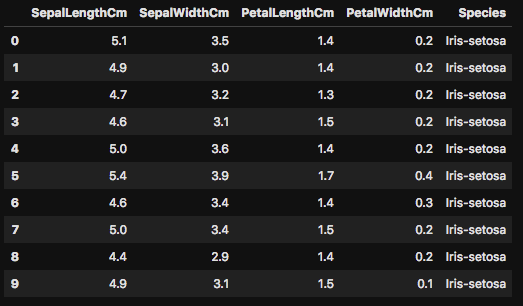
次はもっと細かく指定をしてデータを確認してみましょう。Pandasでは、複数のカラムの指定や、さらには条件を指定してフィルターをかけることも可能です。とても便利な機能で、よりデータの詳細部分を確認するのに頻繁に使いますので、これもやってみましょう。

こちらは、「Iris-setosa」の「SepalLengthCm」が5.5より小さいデータを表示してみました。このように、特的の条件でどのようなデータがあるのかを把握するのは非常に重要なことです。
最後に「Species」と「SepalLengthCm」のみをフィルターしてみましょう。最初の10行のみを下記のコードでは表示させてます。
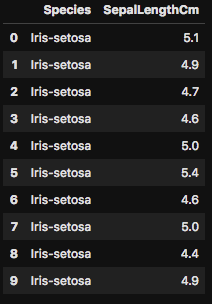
如何でしたか?ここで紹介したものは初歩的な操作のみですが、データ解析を行う際に頻繁に使われる機能です。全てを覚えるのは非効率ですが、基本的な操作方法を覚えておくと、よりスムーズにデータ解析を行うことができます。
データフレームの順番の並び替え(ソート)
次にデータの順番の並び替えも軽く触れておきましょう。常にとは言いませんが、データフレームの並び替えを行う場面も出てきます。機械学習でモデル訓練前にはデータフレームをランダムに並び替えをするのが一般的ですが、データ解析時には上昇順、下降順のような並び替えを行う場合もあります。
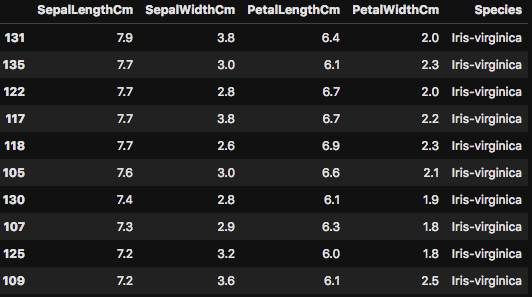
こちらは「SepalLengthCM」のカラムの値に対して、下降順で並び替えを行いました。今回のデータは全データで150しかありませんので、あまり並び替えをしても意味を為さないですが、これがもっと大規模なデータになると、一定の条件でフィルターをして、さらに並び替えをするなどの処理を行いながらデータ解析を行うことがあります。
外れ値の確認
次はデータフレームの欠損について確認してみましょう。データセット内で null を探す場合は、 isnull() の関数が非常に便利です。 null とは空白、つまり欠損しているデータの事です。
機械学習で使うアルゴリズムなどのほとんどのケースで、データに欠損があると正常または全く動かすことができません。ですので、モデルの構築をする前にデータセットの欠損を探して、何かしらの値で代入したり、またはそのデータを削除したりする必要があります。
今回のアヤメのデータセットは学術的な利用もされている初歩的なデータセットなので、欠損などはありませんが…実際の仕事などで扱うデータには欠損が無いのがむしろ珍しいくらいです。
では、早速例題のデータセットで欠損を確認してみましょう。
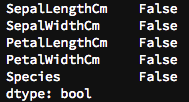
今回のデータセットでは欠損は確認できませんが、一般的には欠損があるのが普通です。欠損が見つかった場合、一番シンプルな処理方法としては、その欠損が含むデータを削除してしまうことです。
ただし、例えば今回のように比較的小さいデータセット(全件150)で、仮に3割に欠損が見つかってしまい、それを全て削除してしまうと、モデル訓練に使えるデータがそれだけ減ってしまう=最終的な精度に大きな影響が出てしまいますよね。
そのような場合は、近似したデータの平均や中央値などを代入したり、他の計算で代入値を導き出したりします。欠損の扱いに関しては、また後日より詳しい記事でご紹介させて頂ければと思います!
まとめ
如何でしたでしょうか?今回は、データサイエンティスト入門として探索的データ解析(EDA)の初歩的な内容をまとめました。
次のステップとして、次はより実践的なデータを触りながら機械学習入門をしてみては如何でしょうか?1時間〜3時間程度で行える初心者向けチュートリアルを公開していますので、是非挑戦してみてください。
初心者向けの機械学習入門チュートリアル
【Kaggle初心者入門編】タイタニック号で生き残るのは誰?
Amazon SageMakerを使って銀行定期預金の見込み顧客を予測【SageMaker +XGBoost 機械学習初心者チュートリアル】
機械学習をすでに触ったことがある方はこちらもオススメ
初心者のための畳み込みニューラルネットワーク(MNISTデータセット + Kerasを使ってCNNを構築)
以上となります!最後までお付き合いくださいして、ありがとうございます。
codexa機械学習チーム ウィリアム


とても勉強になる記事ありがとうございます。
データフレームのフィルタリングのふたつの条件を設定する時の、「「SepalLengthCm」が5.5より小さいデータを表示してみました。」は「5.5より大きい」ではないでしょうか?