「データ」という言葉は非常によく使われる言葉です。AIや機械学習も、データを大量に収集し、それらを学習することで予測を立てています。しかし、データを大量に収集できれば、残りの作業をすべてAIが行ってくれるわけではありません。AIがより精度の高い予測を出すためには、これらのデータをどのように処理するかが重要になってきます。
データには大きく分けて量的データとカテゴリカル(質的)データの2種類が存在します。量的データは身長や時刻などの数値として意味があるものを指します。逆にカテゴリカルデータは性別や順位などの分類や区別を行うためのデータです。収集したデータの特徴を捉えることはデータ分析にとって重要な技術です。特に、カテゴリカルデータに関しては、そのままの形ではデータ分析で扱いにくい場合があります。そのため、前処理を行い、扱いやすいデータに直してあげる必要があります。
本稿ではカテゴリカルデータに対する前処理に注目し、機械学習でもよく用いられるダミー変数について解説していきます。また、後半では実際のデータセットを用いたOne-Hotエンコーディングの実装方法も解説します。本稿が機械学習を勉強し始めた方、kaggleなどのデータ分析コンペティションに挑戦したいと考えている方のお役に立つことができれば幸いです。
ダミー変数の概要
この節では、ダミー変数の概要について説明していきます。まずはダミー変数について正確に理解し、その後、実際のデータセットを使用した実装方法に触れていきましょう。
ダミー変数の定義
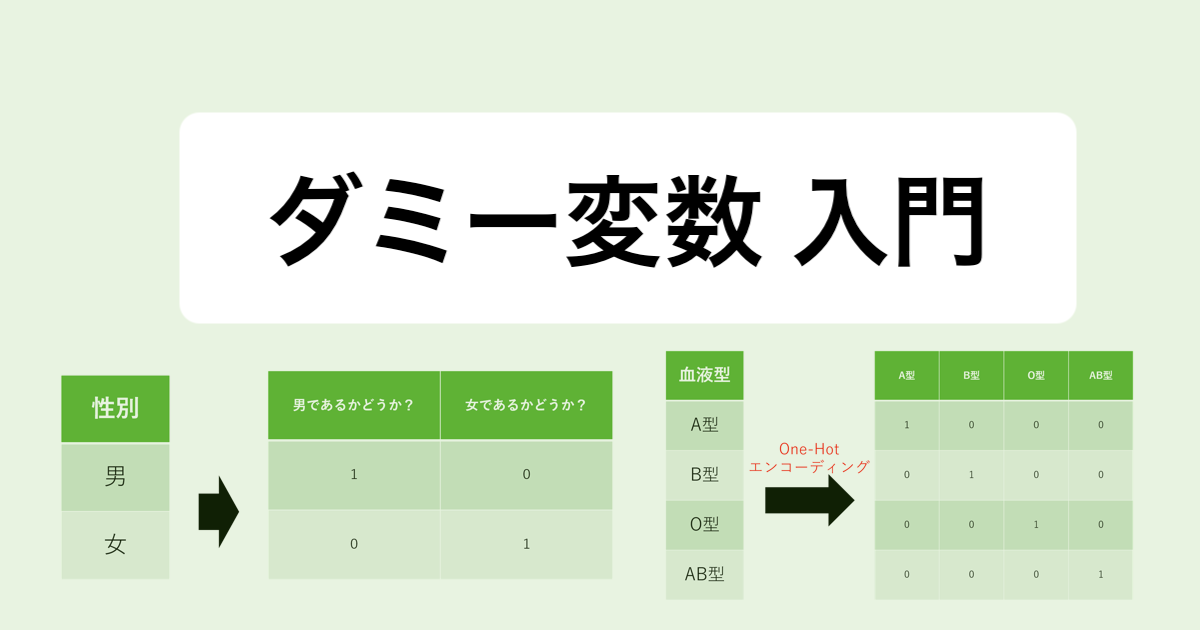
ダミー変数とは、カテゴリカル(質的)データを0又は1で表現した変数のことです。
例えば、「性別」の列に「男性」と「女性」というカテゴリカルデータが存在したとします。このデータは数値ではないので、実際にデータ分析を行うには少し扱いづらいです。この時、「男性であるかどうか?」、「女性であるかどうか?」をそれぞれ1と0で表します。このように数値として扱えないデータを0と1に数値化する際に用いられる変数がダミー変数です。

ダミー変数の定義を「カテゴリカルデータを0と1で表現した変数のこと」と記載しましたが、実施にはカテゴリカルデータにも分類が存在します。ダミー変数についての詳細に触れる前に、カテゴリカルデータの定義についても確認しておきたいと思います。カテゴリカルデータには順序尺度と名義尺度が存在します。この2つの尺度の違いはダミー変数にとって重要な内容なため、しっかりと理解しておきましょう。
順序尺度(Ordinal scale)
順序尺度は数値自体は意味を持たないが、数値の順序に対して意味があるものです。例えば、地震の震度などがこれに相当します。震度は数字が大きくなるにつれて揺れも大きくなりますが、震度3が震度1の3倍強いわけではありません。そのため、震度にを示す数値自体や数値の間隔には意味を持たず、数値の大小関係のみが意味を持つことになります。
名義尺度(Nominal scale)
名義尺度は数値自体に意味がないのに加えて、順序に対しても意味がないものです。例えば、性別や血液型などがこれに相当します。血液型は数値ではないので、「A型」「B型」「O型」「AB型」をそれぞれ「1(A型)」「2(B型)」「3(O型)」「4(AB型)」の数値として置き換えて考えてみます。しかし、これらの数値に意味はありません。「4(AB型)」が「1(A型)」の4倍の何かを持っているわけではありません。同様に、順序も存在していません。あくまで分類のための名前として、それぞれのデータが独立して成り立っています。
この2つの尺度について理解することができたでしょうか?用語を聞くと難しく感じるかもしれませんが、ダミー変数自体は0と1のシンプルな変数です。この2つの尺度を理解した上で実際にダミー変数が用いられる場面を確認してみましょう。それほど難しくは感じないはずです。
ダミー変数が用いられる場面
カテゴリカルデータに存在する2つの尺度を確認したところで改めてダミー変数の話に戻ります。実際のダミー変数は、先に述べた2つの尺度の内、名義尺度の方に適用されることが一般的です。そのため、ダミー変数を更に詳細に定義すると「名義尺度のカテゴリカルデータを0または1で表現した変数」ということになります。何度も述べますようにダミー変数は0と1のみの値しか使用しません。順序を表現することは0と1の値だけでは困難なため、ダミー変数が用いられることは基本的にはありません。
実際に順序尺度と名義尺度のカテゴリカルデータをダミー変数の定義に基づいて表現してみましょう。
順序尺度をダミー変数で変換した場合
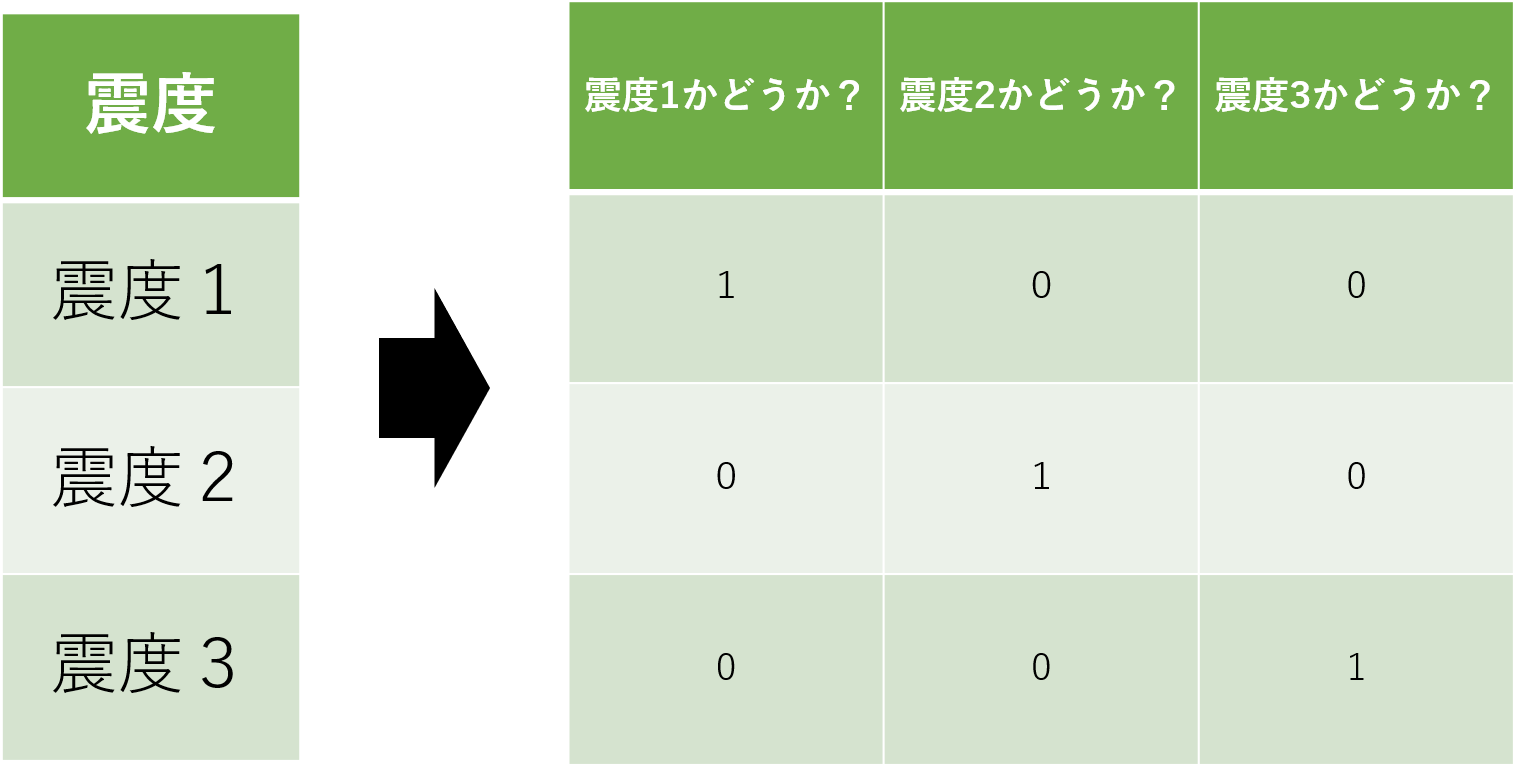
順序尺度をダミー変数で変換した場合を見てみましょう。「震度」の列には「震度1」「震度2」「震度3」を表した変数が存在しています。それをダミー変数を用いて変換すると3列の表になります。この時の2つの表の違いに着目してみましょう。
震度の列には大小関係が存在しています。揺れは「震度2」が「震度1」よりも大きく、「震度3」は「震度2」よりも大きいことは既知です。変換前の表は震度の変数が順番に並んでいるため、大小関係を認識することができます。対して、変換後の表はそれぞれの震度を3列に分けて表現されています。つまり、それぞれの震度が独立して存在していることになります。このような変換を行なってしまうと、震度自体を数値に変換することはできていますが、震度に対する大小関係が認識できなくなってしまっています。
名義尺度をダミー変数で変換した場合
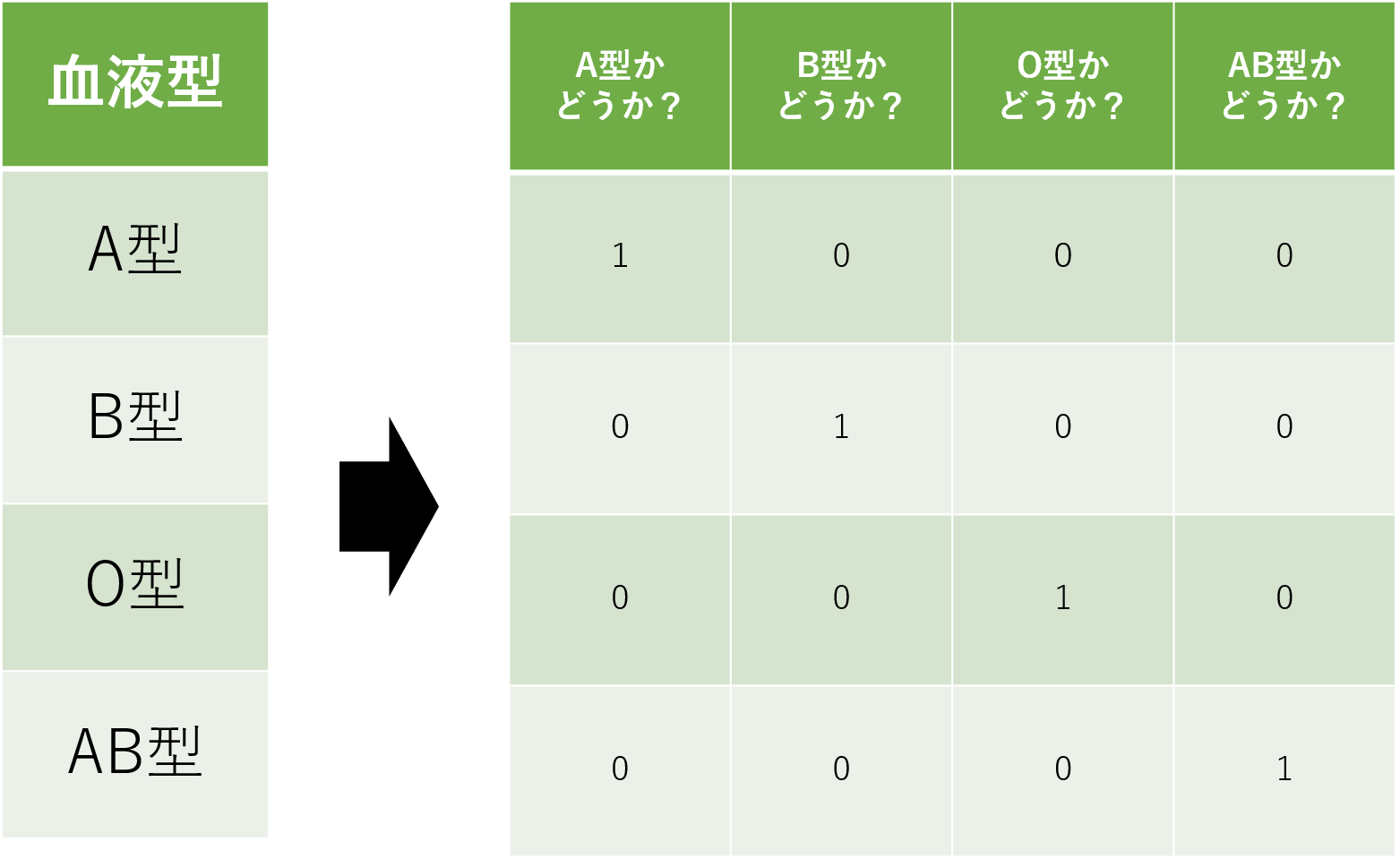
名義尺度をダミー変数で変換した場合を見てみましょう。「血液型」の列には「A型」「B型」「O型」「AB型」を表した変数が存在しています。それをダミー変数を用いて変換すると4列の表になります。この時の2つの表の違いに着目してみましょう。
血液型には元から大小関係は存在していません。変換前の表に注目しても血液型が4種類存在しているというだけで、それぞれの血液型に差はなく、平等に扱うことができます。ダミー変数を用いた変換後の表も見てみましょう。変換後の表ではそれぞれの血液型が4つの列で表現されています。これも、それぞれの血液型が独立して存在していますが、血液型自体に大小関係は存在していないため、問題ありません。
順序尺度と名義尺度をダミー変数で変換した時の違いについて触れてきました。ここまでの説明で、ダミー変数を名義尺度のカテゴリカルデータに適用する理由はご理解いただけたかと思います。次はダミー変数を用いたOne-Hotエンコーディングと呼ばれる前処理の手法について触れていきます。
One-Hotエンコーディングとは
急にOne-Hotエンコーディングという名前が登場したため、戸惑われている方もいらっしゃるかもしれませんが、基本的にはここまでに説明した「ダミー変数を用いた変換」と同義です。機械学習の分野ではダミー変数を用いた前処理をOne-Hotエンコーディングと呼びます。先に述べた血液型のように、数値として扱えない型などで表されたデータを数値に変換する際に使用されます。
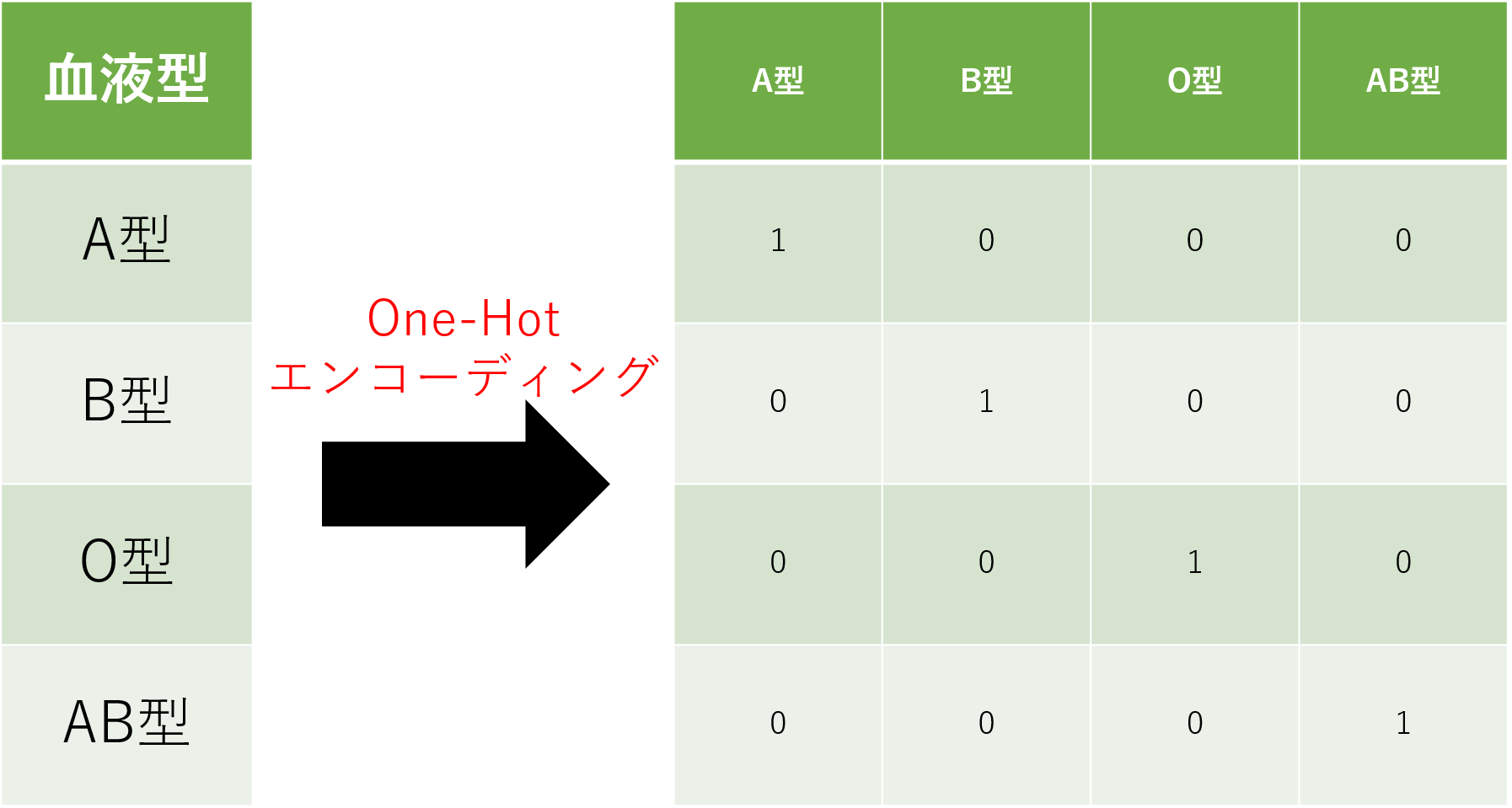
One-Hotエンコーディング自体はシンプルな手法ですが、同時に注意点も存在します。上記の図を見ても分かるように変換前の表は4×1の大きさなのに対し、変換後の表は4×4の大きさになっています。つまり元の表に存在するユニークな値の数だけ、変換後に列が作られる事になります。今回は4種類程度でしたが、ユニークな値の数が膨大になればその分の列を作成しなければなりません。つまりメモリの消費量が大きくなります。大規模データセットに対してOne-Hotエンコーディングを行う場合は、そういった点も考慮する必要があります。
実際のデータ分析では様々な前処理を駆使してデータを扱いやすい形に変換させていきます。カテゴリカルデータに0から順番に番号を振るLabelエンコーディングや、カテゴリカルデータの出現回数をカウントするCountエンコーディングなどが存在します。機械学習を勉強される方にとっては頻出用語ですので、様々なエンコーディング手法を調べてみてください。今回のようなデータ分析コンペティションでよく使用される前処理が記載された本なども発売されています。業務よりもコンペの方に興味がある方は読んでみてください。(参考:Kaggleで勝つデータ分析の技術)
ここまでは理論を中心に説明してきましたが、この後は実際にPythonを用いてOne-Hotエンコーディングを実装していきたいと思います。理論と実装の両方を抑え、ダミー変数とOne-Hotエンコーディングをしっかりと理解しましょう。
One-Hotエンコーディングの実装
本節では、One-Hotエンコーディングを機械学習ライブラリでよく用いられるpandasとscikit-learnを用いた2通りの手法で実装していきます。本稿では、Google Colabを用いて実装していきます。本稿は2021年3月8日時点でコードの実行確認を行いましたので、Google Colabのデフォルトのバージョンが変更されない限り、ライブラリをそのままインポートすれば同じように実装可能です。是非、ご自身でも実装してみてください。(参考:Python 機械学習ライブラリを23個一挙紹介!データ処理から深層学習まで完全網羅・Google Colabの知っておくべき使い方)
それではOne-Hotエンコーディングの実装を行なっていきます。はじめに、必要なライブラリを読み込みます。
データセットにはkaggleのチュートリアルで最も有名なTitanicのデータセットを利用します。Titanicのデータセットはseaborn上に用意されているので、今回はそちらを利用します。kaggle上で提供されるTitanicとseaborn上のTitanicのデータセットは若干の違いがあるため、注意してください。
Titanicコンペティションの解説はAIマガジンの【Kaggle初心者入門編】タイタニック号で生き残るのは誰?でも紹介しています。今回は投稿は行わないため、投稿まで行いたい方はこちらを参考に挑戦してみて下さい。(参考:Titanic – Machine Learning from Disaster)

データセットの最初5行が表示されました。今回はOne-Hotエンコーディングの実装が目的なため、データセットの中から名義尺度であるものを抜き出します。変換後の結果が分かりやすいようにsex(性別)とembark_town(出航地名)を使用してみましょう。
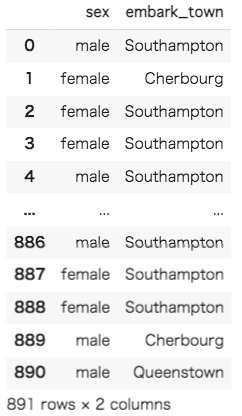
sex(性別)とembark_town(出航地名)を抜き出すことができました。念のため、欠損値を確認して、存在していれば削除してしましょう。
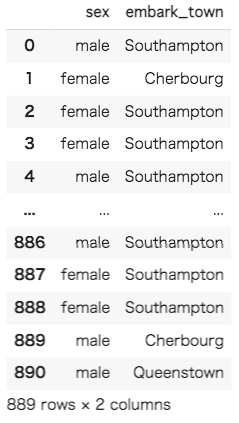
embarkedに欠損値が2つあったため、対象の行を削除しました。次に、それぞれの列に何種類のカテゴリカルなデータが存在するのかを調べたいと思います。そのために、それぞれの列からユニークな値を表示します。
ユニークな値を調べたところ「sex」の列には「male」と「female」の2種類、「embark_town」の列には「Southampton」と「Cherbourg」と「Queenstown」の3種類の値が存在することが分かりました。これで、One-Hotエンコーディングを行うための準備が整いました。まずはpandasのget_dummies()を用いてOne-Hotエンコーディングを実装していきます。pandasのget_dummies()をデフォルトで使用すると、変換後の列名が「変換前の列名_変換前の変数名」になります。引数を渡すことによって、欠損値をダミー変数で扱ったり、列名を変更したりすることができます。詳しく知りたい方はpandasの公式ドキュメントを参考にしてみてください。(参考:pandas.get_dummies(pandas公式)・現場で使える!pandasデータ前処理入門)
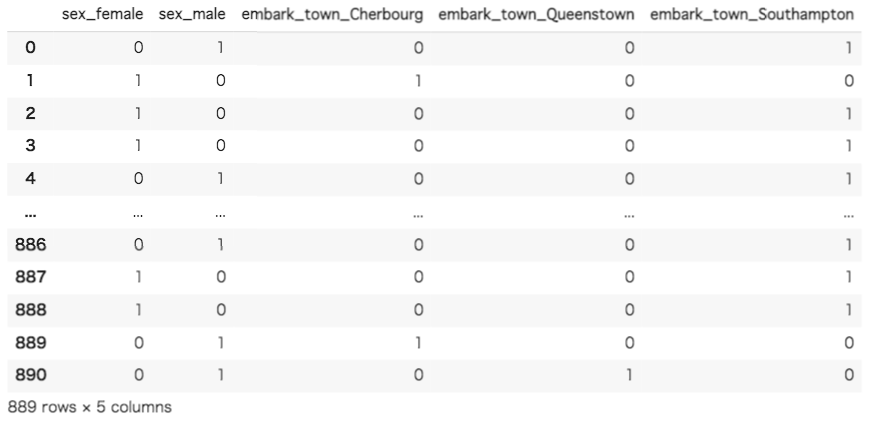
ダミー変数によってOne-Hotエンコーディングが行われたことが確認できました。前半で説明したように、「sex」の列が「sex_female」と「sex_male」に、「embark_town」の列が「embark_town_Cherbourg」と「embark_town_Queenstown」、「embark_town_Southampton」として新しい列に変換されています。確認すると、変換前の列に存在した変数が新しい列では1と0で表現されています。
続いてscikit-learnのOneHotEncoder()を用いてOne-Hotエンコーディングを行なっていきます。OneHotEncoder()では引数をsparse=Falseに設定し、返り値を配列にして見やすくしています。sparse=Trueにした場合は疎行列が返り値に設定されます。その次の行の処理では、dtypes=intにすることで整数値を返しています。デフォルトではfloatになっています。OneHotEncoder()には他にも引数を設定できるので、興味がある方はscikit-learnの公式ドキュメントを参考にしてみてください。(参考:sklearn.preprocessing.OneHotEncoder(scikit-learn公式))
返り値がnumpyのarrayになってます。scikit-learnのOneHotEncoder()ではDataFrameを返すことができません。そのため、pd.Dataframe()を用いてデータフレームに直します。分かりやすいようにpandasのget_dummies()を使用した場合と同様の列名を指定します。
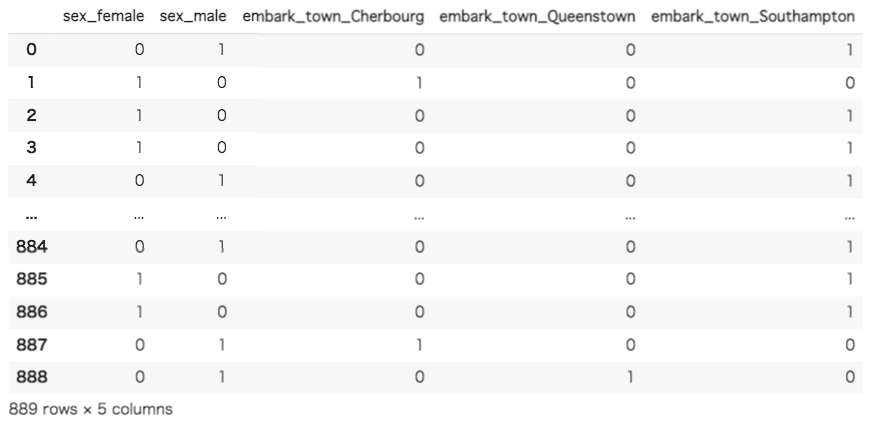
ダミー変数によってOne-Hotエンコーディングが行われたことが確認できました。今回は欠損地を予め削除したため、問題は起こりませんでしたが、scikit-learnのOneHotEncoder()はデータ内の欠損値に対応出来ません。そのため、今回のように予め欠損値を削除しておくか、平均値などで埋めておく必要があります。pandasのget_dummies()ではデフォルトでは欠損値をすべての列で0として扱うため、エラーの発生という面では起こりにくくなります。
ここまで、pandasのgetdummies()とscikit-learnのOneHotEncoder()の2つの実装を紹介してきました。一見するとget_dummies()の方が扱いやすそうに感じますが、データによっては注意が必要です。pandasのDataFrameはnumpyの配列と比較してメモリの消費量が多い傾向があるため、機械学習などで使用される大規模データセットを用いた際にはメモリエラーとなる場合があります。大規模データセットを使用する際にはOneHotEncoder()を使用したり、sparse=Trueに設定して疎行列を出力するなどの工夫が必要です。
ダミー変数を扱う際には、多重共線性と呼ばれる問題が発生する場合があります。多重共線性を理解するためには数学的な知識が必要になってくるため、詳細について本稿では説明しません。しかし、統計学と機械学習の両分野において重要な用語ですので、興味がある方は調べてみるとをオススメします。
まとめ
いかがでしたでしょうか。本稿を通して、ダミー変数及び、One-Hotエンコーディングについて少しでも理解を深めることができたら幸いです。データに対する前処理は機械学習の分野では避けては通れない道です。ダミー変数だけでなく、多くの前処理を勉強し実践してみてください。正確で効果的な前処理を実装できるようになれば、機械学習エンジニアに一歩近づくはずです。
codexaでは機械学習の勉強を簡単に始められるコースをご用意しています。前処理についても基礎からしっかりと抑えることができます。是非、ご受講をお待ちしております。

