
機械学習モデルを構築する際に欠かせないのが、機械学習ライブラリです。様々な機械学習ライブラリがインターネット上で提供されていることが、昨今の機械学習ブームを支えているのは間違いありません。
しかし、一言で機械学習ライブラリといっても、その用途は様々です。どのライブラリを、機械学習モデル構築の流れの中のどの工程で用いればいいのかがわかっていなければ、スムーズにモデル構築を進めることはできません。
そこで本稿では、機械学習ライブラリとは何なのか、それぞれのライブラリがどのような特徴を持つのかをまとめました。機械学習モデル構築の流れと併せて、機械学習ライブラリについての確かな知識を身につけましょう。
この記事の目次
機械学習ライブラリの定義と実装の流れ
まずは、機械学習ライブラリの定義について確認し、機械学習モデル実装の流れを概説します。これによって、次節で紹介するライブラリを、それぞれどのような場面で利用すればいいのかイメージしやすくなるでしょう。
ライブラリとは
ライブラリとは、「特定の処理を実行するためのプログラムをまとめたもの」です。例えるならば、システム構築のための道具箱のようなものでしょうか。他人が作成したプログラムも利用することができるため、大幅な作業時間の短縮になります。また、目的に応じて適切なライブラリから適切なプログラムを呼び出して用いることで、実行できる処理の幅を飛躍的に広げることができます。
なお、ライブラリと似た用語にフレームワークがありますが、厳密にはこれらは異なります。フレームワークは「全体が大まかに設計されたプログラムの集合体」のようなものです。ライブラリが道具箱ならば、フレームワークは雛形です。フレームワークを活用しつつ、細部を目的に合わせてカスタマイズすることで、独自の処理を実行することができます。
機械学習ライブラリとは
前述のライブラリの説明に則ると、機械学習ライブラリとは、「機械学習モデルを構築するためのプログラムをまとめたもの」です。なお、本稿では、機械学習を実際に構築する際に用いるライブラリを「狭義の機械学習ライブラリ」とし、実際のモデル構築には用いないものの、機械学習モデル開発の流れの中で利用するライブラリを「広義の機械学習ライブラリ」として扱います。言い換えると、狭義の機械学習ライブラリは機械学習のモデリング機能を持つライブラリを、広義の機械学習ライブラリは機械学習モデル構築に関わる全てのライブラリを指します。
機械学習モデル構築の流れ
機械学習ライブラリを紹介する前に、機械学習モデル構築の流れを概観しておきます。機械学習モデルは、一般に以下のような流れで構築します。
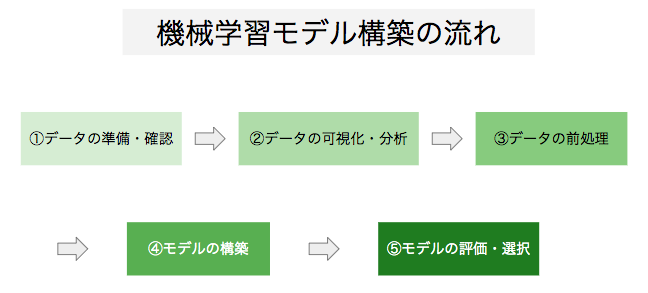
1. データの準備・確認
コンピュータに学習させるデータを準備し、コンピュータに読み込ませて、学習に使えるようにデータを整形します。例えば、複数のデータセットを一つのデータセットにまとめたり、適切な変数名をつけなおしたりします。
2. データの可視化・分析
次に、データを2次元や3次元の様々な図やグラフを用いて表現し、その特徴を分析します。これにより、異常なデータが含まれていないかどうかを確認したり、重要な変数を見つけだしてモデル構築のヒントを得たりすることができます。(参照:EDA 探索的データ解析とは?)
3. データの前処理
機械学習モデルの構築に入る前に、データの前処理を行います。この工程により、学習が正しく実行されるようにするとともに、モデルによる予測の精度を高めることができる場合があります。具体的には、欠損値を何らかの値で埋めたり、データを標準化したりします。
4. モデルの構築
機械学習モデルを構築します。データの量や種類などの特徴に合わせて、適切なライブラリやフレームワークを選択してモデルを構築し、コンピュータによる学習を行います。
5. モデルの評価・選択
データを学習させたモデルがどれくらいの精度で予測可能なのか、評価指標を用いて確認します。評価指標の値を分析し、より良いと思われるモデルを構築して予測・評価を繰り返し、最も性能がいいモデルを選択します。(参考:機械学習の評価指標 分類編)
主な機械学習ライブラリ
機械学習モデル構築の流れを把握できたところで、主な機械学習ライブラリについて解説していきます。まずは、広義の機械学習ライブラリから見ていきましょう。
Numpy

<引用:numpy公式 >
Numpy(ナンパイ)はPython用の数値計算ライブラリです。コアとなる部分がコンパイル型の言語であるC言語で書かれているため、インタプリタ型のPython自体よりも早く演算処理を行うことができます。また、大規模な多次元配列や行列の計算を行うことができ、Pythonにおける数値計算に関してはデファクトスタンダードになっていると言っても過言ではないでしょう。公式ウェブサイトに掲載されているnumpyのケーススタディには、クリケットの分析や、アインシュタインが存在を予測した重力波の検出についての記事があります。多様な分野で認められ、活用されているライブラリである証拠ですね。機械学習モデル構築においては、大規模なデータを演算する際に活用することができます。
> 公式サイト
> NumPy 入門無料コース
pandas

<引用:pandas公式 >
pandas(パンダス)はPython上で動くデータ処理・分析用ライブラリです。最大の特徴は、データフレームという行列形式のデータを処理するための様々な方法を備えていることです。データの結合や変形、特定の行や列の抜き出しや挿入、特定の行や列の値に基づくグループ化、さらにはCSV・テキスト・エクセルなどのデータの読み書きと、データセットに関して極めて幅広い処理が可能です。ゆえに、pandasを使いこなせれば、収集された生データを機械学習モデルで分析可能な状態に整形することができます。
> 公式サイト
> pandas 入門無料コース
> 現場で使える! pandasデータ前処理入門(入門書籍 / Amazon)
matplotlib

<引用:matplotlib公式 >
次に、matplotlib(マットプロットリブ)を紹介します。matplotlibはMATLABというデータ解析用の言語を模倣して作られた、Python用のデータ可視化ライブラリです。主にPythonで書かれていますが、前述のnumpyを始め他のライブラリも活用することで処理性能を向上させ、大規模なデータの可視化に対応しています。公式サイトのギャラリーにあるように、matplotlibを使うことで、データを非常に多様な方法で可視化することができます。機械学習モデルの構築においては、可視化を通して、数値だけではわかりづらいデータの分布やデータ同士の連関についての理解を深めます。そうすることで、不必要なデータを除外したり、モデル構築の方針を立てたりすることができるのです。
seaborn

<引用:seaborn公式 >
matplotlibと並んで有名かつ便利な可視化ライブラリにseaborn(シーボーン)があります。seabornの主な特徴については、seabornについての記事でもご紹介したように、以下の点が挙げられます。1点目は、matplotilbと比べて洗練された図を描くことができることで、2点目は、matplotlibと比べて少ないコードで可視化が可能であることです。matplotlibの方が一般に広く活用されてはいるものの、seabornも可視化には非常に便利なライブラリとなっています。
> 公式サイト
SciPy

<引用:SciPy公式 >
SciPy(サイパイ)は、数値積分や最適化、線形代数や統計的な手法による計算などの複雑な数値処理を行うためのライブラリです。機械学習モデル構築においては、データの前処理などに活用することができます。
> 公式サイト
ここからは、機械学習ライブラリの中でも、実際に機械学習モデルを構築する際に用いる狭義の機械学習ライブラリや機械学習フレームワークについて解説します。
scikit-learn

<引用:scikit-learn公式 >
まずは、機械学習ライブラリの定番であるscikit-learn(サイキット・ラーン)についてご説明しましょう。scikit-learnは前述のNumpy, SciPy, matplotlib上で動作する、オーソドックスな機械学習ライブラリです。scikit-learnには、大きく分けて「回帰」、「分類」、「クラスタリング」、「次元削減」、「データの前処理」、「モデルの評価と選択」という6つの機能があり、前処理以降のモデル構築プロセスを広範にカバーしているのが最大の特徴です。サンプルのデータセットや公式の丁寧なガイドも用意されているので、手軽に機械学習を試すこともできます。
> 公式サイト
> scikit-learn 入門:6つの機能と分類・回帰の実装方法を徹底解説!
XGBoost・LightGBM
XGBoost(エックスジーブースト)とLightGBM(ライトジービーエム)は、どちらも勾配ブースティングによる機械学習のフレームワークです。勾配ブースティングとは、決定木アルゴリズムに基づいた機械学習手法で、Kaggleのコンペティションでも非常に人気があります。scikit-learnのように前処理まで対応しているわけではありませんが、高精度の機械学習モデルを構築するという観点から見て非常に優れたフレームワークです。また、どちらも、PythonだけでなくCやRなどの複数のプログラミング言語に対応しています。scikit-learnでのモデル構築に習熟してきたなと感じたら、これらのフレームワークを活用してみると良いでしょう。
> XGBoost 公式サイト
> XGBoost 徹底入門コース
> LightGBM 公式サイト
> LightGBM 徹底入門
深層学習(ディープラーニング)のフレームワーク
さて、機械学習ライブラリについて一通り学んだので、本節では機械学習の中でも特に注目を集めている深層学習のフレームワークを見ていきましょう。「そもそも深層学習って何?」と疑問をお持ちの方は、こちらを参考にしてください。
TensorFlow

<引用:TensorFlow公式 >
まずは、Googleが提供している機械学習ライブラリのTensorFlow(テンソルフロー)から解説します。TensorFlowは機械学習ライブラリですが、深層学習(ディープラーニング)にまで対応しているのが特徴です。また、PCでPythonを用いて利用するだけでなく、JavaScriptやモバイルデバイス、クラウド上での利用にも対応したバージョンがあり、様々な場面で利用することができます。さらに、TensorBoardという可視化ツールが付属しているため、図を用いて直感的に理解しつつ、モデル構築を進めることができます。
> 公式サイト
> TensorFlow 徹底入門
Keras
Keras(ケラス)は、TensorFlowをはじめとしていくつかの機械学習ライブラリ上で動かすことができる深層学習ライブラリです。特徴としては、いくつものライブラリ上で動かせる点に加えて、シンプルで簡単に深層学習モデルを構築できる点や、分散処理に対応していることで効率的な学習ができる点などが挙げられます。
> 公式サイト
> KerasによるCNN
> Kerasによる時系列モデル
PyTorch

<引用:PyTorch公式 >
Facebookの人工知能研究グループが開発したPython用の機械学習ライブラリが、Pytorch(パイトーチ)です。セールスフォース・ドットコムやスタンフォード大学での開発に利用されています。また、後述のChainer(チェイナー)を開発した日本の有力なベンチャー企業「Prefferd Networks」が、研究開発基盤を自社のChainerからPyTorchに移行したことからも、PyTorchの競争力の高さが窺えます。そんなPytorchの特徴として挙げられるのが、操作方法がNumpyに類似している点です。日頃、numpyを扱うPythonエンジニアであれば容易に扱えるのは嬉しいですね。また、ニューラルネットワークの構築の際に必要となる「計算グラフ」が動的に構築される点(Define-by-Run方式)で、TensorFlowやKerasと異なります。さらに、分散処理への対応によるパフォーマンスの最適化や、ツールやライブラリといった開発エコシステムの充実、主要なクラウドプラットフォームにも対応している点なども特徴といえます。
Chainer

<引用:Chainer公式 >
Chainer(チェイナー)は、Prefferd Networksによって開発され、2015年にオープンソースとして公開されたディープラーニングフレームワークです。2019年に、Prefferd Networksの開発基盤のPytorchへの移行に伴い、Chainerは新たな開発を停止してメンテナンスフェーズへと移行しました。しかし、日本企業が開発したフレームワークであるため、日本語で得られる情報量も多く、特に日本では他の深層学習フレームワークと並んで人気があります。PyTorchにも採用されているDefine-by-Run方式をはじめに採用した点が特徴です。
> 公式サイト
データの特徴別機械学習ライブラリ(自然言語、画像、音声)
さて、この節では、データの特徴に応じて用いる専門性の高いライブラリについて解説します。自然言語データ、画像データ、音声データはそれぞれ特有の性質があるため、独自の分野が形成されています。ライブラリに関しても、それぞれのデータに特化したものをまとめてご紹介していきます。
自然言語処理
まずは自然言語処理です。自然言語とは人間が用いる言語のことで、コンピュータが処理する機械語に対応した表現です。日本語も英語も自然言語の一つです。自然言語処理とは、そんな自然言語を単語単位に分割して、数学的・統計的理論に基づいて解析する技術です。自然言語処理は、Googleなどの検索エンジンやAppleのSiriやAmazonのAlexaといったスマートアシスタント、メールのスパムフィルター、テキストの予測変換、機械翻訳など、様々な分野に活用されています。自然言語処理ライブラリの例としては、以下のものが挙げられます。
- Mecab:オープンソースの形態素解析エンジン。複数のプログラミング言語に対応しており、辞書の追加も容易。(参考:Mecab入門)
- Janome:Pythonで書かれた形態素解析器。辞書も内包されていて利用しやすいのが特徴。
- Chasen:奈良先端科学技術大学院大学松本研究室で開発された形態素解析器。
- JUMAN:京都大学大学院の黒橋・褚・村脇研究室で開発された日本語形態素解析システム。
- GINZA:オープンソース日本語自然言語処理ライブラリ。
画像認識
画像認識とは、コンピュータに大量の画像を読み込ませて学習させることにより、物体の識別を可能にする技術です。自然言語処理技術同様、スマートフォンの顔認証やカメラの顔認識機能、医療現場での病変の検出や自動運転車といったように様々な分野で活用されています。画像認識のためのライブラリには以下のようなものがあります。
- OpenCV:Open Source Computer Vision Libraryの略称。複数のプログラミング言語とOSに対応。
- pillow:Python Imaging Library(PIL)を元にした画像処理ライブラリ。
- scikit-image(サイキットイメージ):画像処理に特化したPythonライブラリ。
音声認識
音声認識とは、デジタル化した音声をコンピュータで学習することで、音声を判別したり、新たな音声を生成するための技術です。活用例としては、SiriやGoogle Home、音声による検索機能、会議の議事録・コールセンターでの問い合わせの文字起こしなどが挙げられます。
- speech recognition:様々な音声認識エンジン、音声認識APIをサポートする音声認識ライブラリ。
- pyaudio(パイオーディオ):PortAudioをPythonで利用可能にするライブラリ。
- Julius:音声認識システムの開発・研究のための、オープンソース汎用大語彙連続音声認識エンジン
まとめ
いかがでしたでしょうか。本稿を通して、どの機械学習ライブラリをどの場面で使うのか、マクロなイメージを掴むことが出来ていたら幸いです。機械学習モデル構築の全体像を知ったところで、各種ライブラリを活用して実際に機械学習モデルを構築してみることをお勧めします。
codexaでは、本文中で参考としてご紹介した記事の他にも機械学習ライブラリの講座を提供しています。どれも無料あるいは数百円で受講可能なので、ぜひこの機会にご利用ください。
- Numpy入門
- Pandas入門
- Matplotlib入門
- XGBoost
- 決定木とランダムフォレスト(Scikit-learn利用)
- はじめての画像認識(OpenCV、Keras利用)

