
突然ですが、皆さんはアンケートの回答を求められた経験はありませんか? 道端で声を掛けられる場合もあれば、飲食店の机の上に置いてある場合もあります。例えば皆さんが機械学習の勉強会に参加していたとします。以下の項目を聞かれた場合、皆さんは何項目記入しますか?
■セミナー来場者アンケート
1. お名前
2. 性別
3. 年齢
4. 住所
5. どのように今回のセミナーを知りましたか?
6. 本日の感想

(引用:いらすとや)
人によって記入する項目は違うと思いますが、来場者全員がアンケートをすべて答えてくれるとは限りません。しかし、もしあなたがセミナーの主催企業の社員であり、このアンケートを利用してデータ分析を行いたいと思っていたとすればデータに穴があることは非常に大きな問題です。未記入部分のデータの扱い方を間違えた場合、データ分析がうまくいかない可能性があります。
機械学習の分野でも、このアンケートのようにデータが完全には揃わない場合があります。特に現実に存在するデータでは整っていない場合の方が多いです。アンケートの例で言えば、未記入の項目があったり、回収時に破れてしまったりして、データの一部が欠損してしまうことが考えられます。データ分析を行う以上はこの欠損した値に対応しなければなりません。本稿では機械学習分野で出現する欠損値の解説と、Pythonによる欠損値の対処法を実装していきます。
前提理解
これから欠損値を説明していく前に理解しておいていただきたいことをお伝えします。「欠損値」という言葉自体は比較的認知されている用語ですが、その性質を正しく理解するにはある程度の数学的知識が必要になります。特に初学者の方にとっては高いハードルとなる可能性があります。現に、欠損値に特化した内容の本が出版されているほどです。加えて、用意されたデータセットに対し、統計学的に正しいと理論づけられる欠損値処理を実装する事はより難しいと言えます。そのため、本稿では欠損値については基礎的な部分を中心に説明・実装していきます。本稿を読んだ後で、より詳細に欠損値について理解されたい方は以下の本を参考にしながら勉強してみてください。(参考:欠測データの統計解析 (統計解析スタンダード)・欠測データ処理: Rによる単一代入法と多重代入法)
欠損値とは?
あるデータ内の変数において、存在しない値を欠損値(missing value)と言います。統計学の分野では以前から存在した欠損値ですが、データ分析において頭を悩ませる原因の1つであることは間違いありません。しかし、欠損値が存在している以上私たちは何らかの手段を取らなければなりません。特にデータ分析の手法の中には欠損値を扱えないものも存在し、そのままにしておくのはリスクがあります。欠損値の性質はデータセットによっても変わるため、正解の対処法を記載することはできませんが、比較的重要なポイントとしては以下の2点があると筆者は考えます。
1つ目は「なぜ欠損が発生したか」ということです。欠損の原因が判明すれば、その部分のデータを補完できる方法を考えることができます。欠損値の部分を正しい値で補完できることが望ましいことは間違いありません。しかし、現実問題として、欠損値を正確なデータで埋めることは困難な場合が多いです。アンケートの記入漏れを一つ見つけるたびに、回答者の方に再記入をお願いしていたのではデータ収集自体が終了しません。それでも欠損の理由を調べることでその後の対処法に活かせる可能性は大きくなります。
2つ目は「どのように欠損値に対処するか」ということです。発生してしまった欠損値に対し、本来のデータからの誤差が少しでも小さくなるように欠損値を補完することが求められます。欠損値を無視したり、独自の値で埋めたり、それ自体を予測したりと手法は様々ですが、根拠のある対処を行わなければなりません。ここで難しいのは欠損値の対処を間違えると本来のデータ自体が歪んでしまうという事です。たとえ素晴らしいモデルを利用したとしても歪んだデータから導き出された予測は精度が落ちかねません。
欠損値の種類
欠損値には大きく分けて3つの種類があります。それぞれの欠損値が特徴を持っているため、その部分を意識しながら見ていきましょう。種類ごとに理解するのは手間かもしれませんが、欠損値に対する対処法は種類によって良し悪しがあるため、しっかりと抑える必要があります。欠損値の種類について、以下の表を参考に解説していきます。
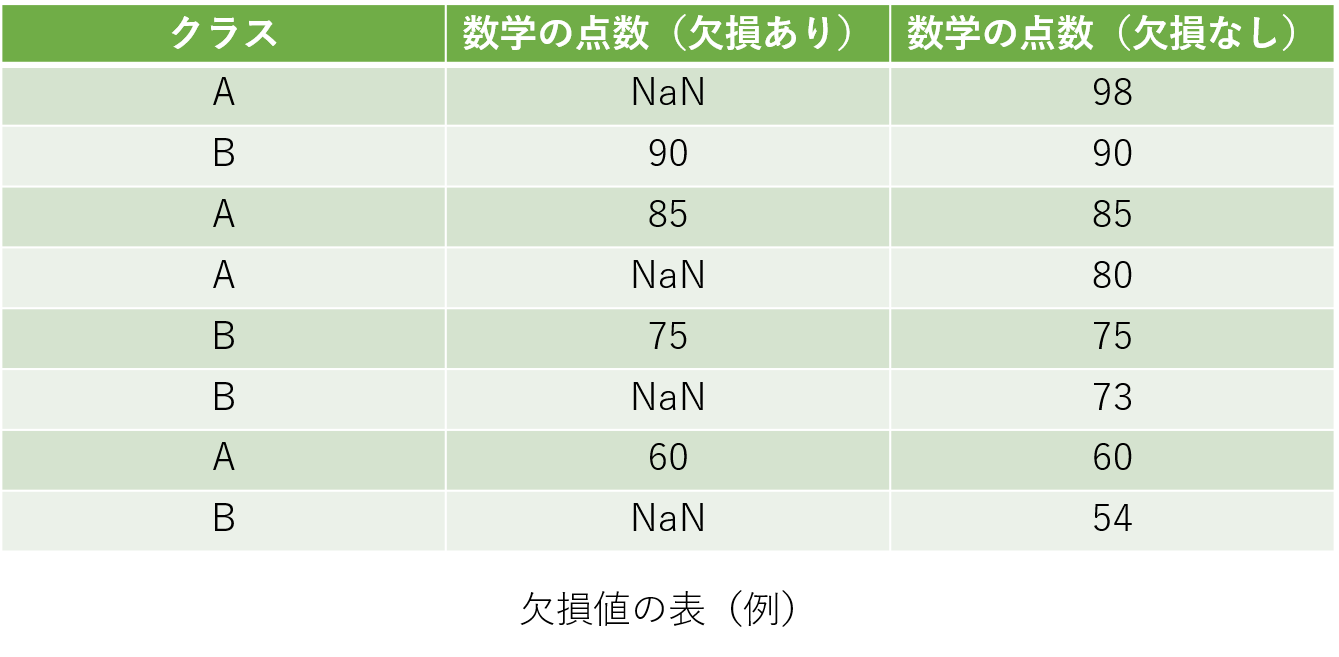
MCAR(Missing Completely At Random)
一つ目はMCARです。MCARは欠損値がランダムに発生している場合を指します。完全にランダムに発生するため、メカニズムの理解自体は簡単です。しかし、欠損値がランダムであるという証明が難しいために、欠損値の発生原因が分かりにくい場合もあります。それでも、欠損が偏っていないため他の2つと比べると比較的対処しやすいという特徴があります。
上の表をみても分かるように、ランダムに欠損が存在しています。今回は分かりやすくするために8行の表を用いていますが、本来のデータセットはもっと膨大な行が存在するので、欠損値の確認はしっかりと行う必要があります。
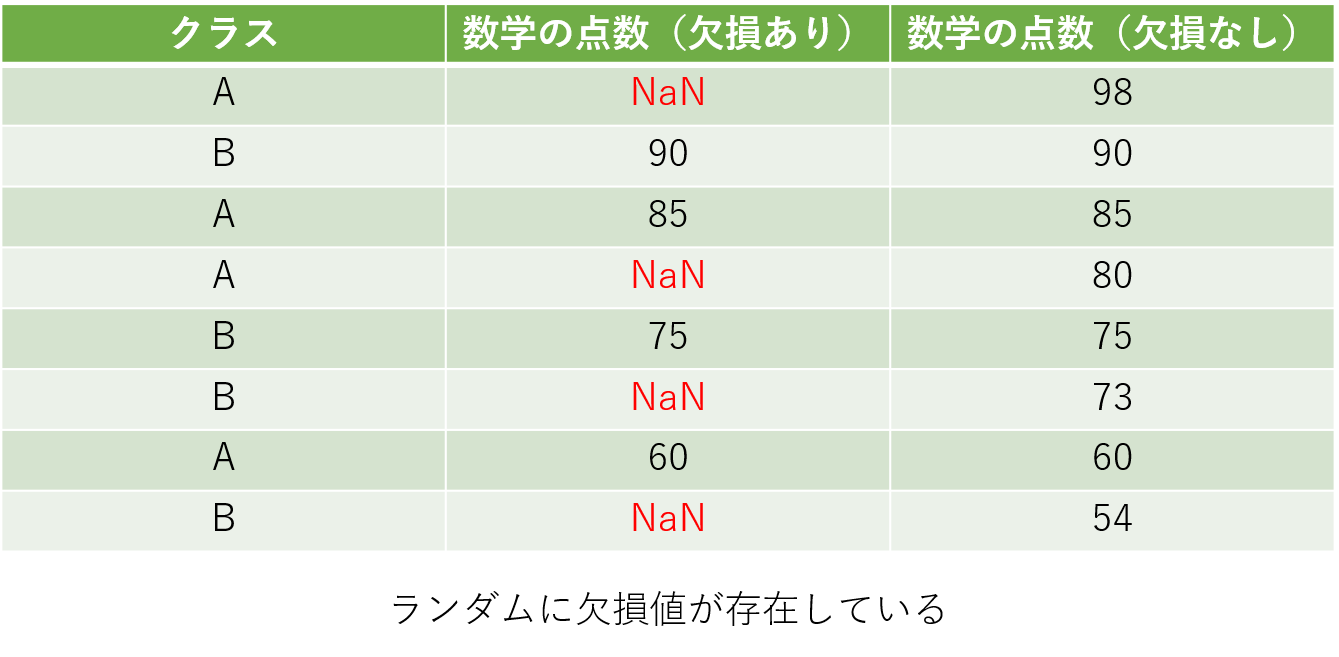
MAR(Missing At Random)
MARは欠損値の有無が別の変数に依存している場合を指します。欠損値が存在する変数だけを見たときには一見するとランダムに欠損が発生しているように見えます。MCARとは異なり、依存先の変数に注意を払いながら対処しなかればなりません。そのため、欠損値処理もMCARに比べて少々複雑になります。
上の表をみても分かるように、欠損値が発生している行がクラスBに集中しています。そのため、「クラスBの生徒はテストを受けなかったのではないか」などの予測が立てられます。こういった予測を考慮した上で欠損値に対応していく必要があります。今回のクラスのような欠損の有無と相関をもつような変数を補助変数 (auxiliary variable) と言います。注意していただきたいのは、MARはあくまで欠損値が他の変数に依存しているという点です。今回のように他の変数に対応した行全てが欠損していなければならないといった制約はありません。
MNAR(Missing Not At Random)
MNARは欠損値の有無がそのデータに依存している場合を指します。依存が自身の数値内容によって影響を受けているため、予測を行うことが難しいという特徴があります。特にこのMNARにはまだ確実な対応手法は存在しません。MNAR自体は状態ではMARとは違いますが、仮にこの欠損値を説明できるような変数を用意でき、欠損値が存在する部分とその変数との依存が解消された場合にはMARになります。
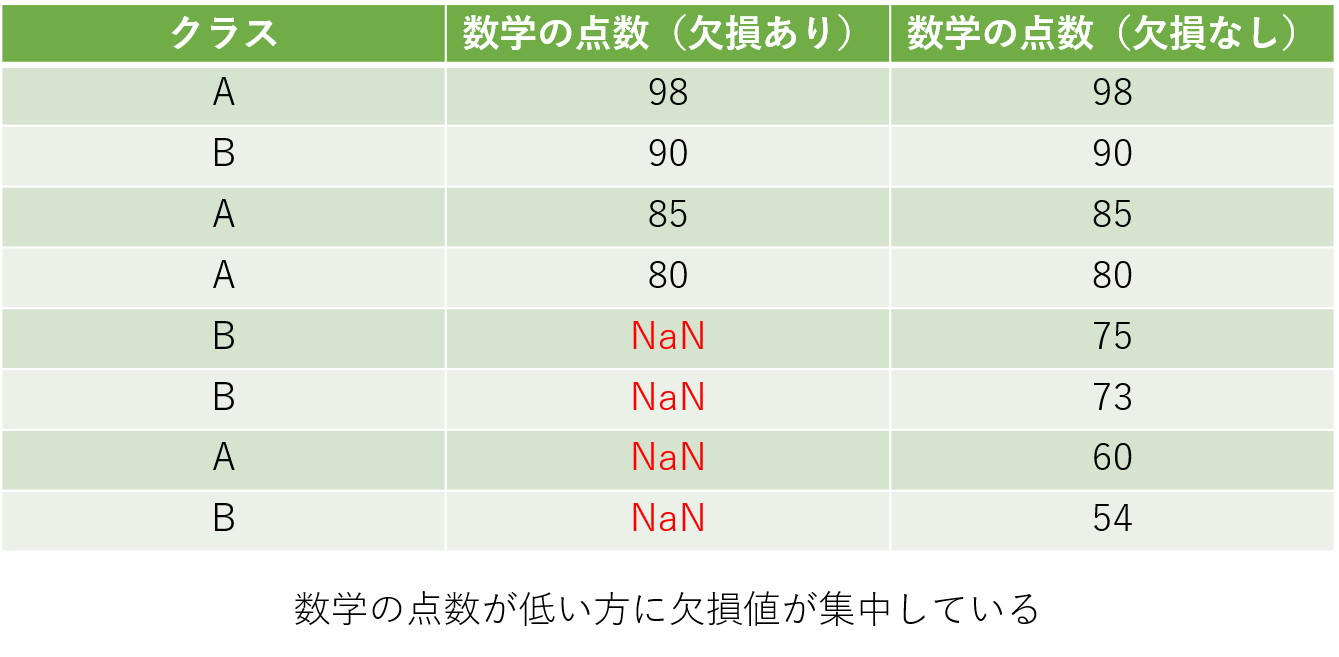
上の表をみても分かるように、欠損値が発生している行が数学の点数が低い方に集中しています。そのため、「点数の低い生徒は記録されなかったのではないか」などの予測が立てられます。他にも、点数の差はありますが、80点までは欠損が発生していないため、「80点未満は不合格な試験であり、不合格者の点数は発表されないのではないか」などの予測を立てることもできます。今回はデータ数が少ないため、正確な理由は不明ですが、欠損が発生しているというそのものに意味がある可能性もあるのでデータをよく確認しながら対処を考える必要があります。
欠損値への対処法
本節では、欠損値への対処法について記載していきます。前章でも述べたように、まずは「なぜ欠損値が発生したか」を知る必要があります。それを知った上で、本来のデータで欠損値を埋めることができれば正しい分析・予測ができるでしょう。しかし、欠損値の発生原因を特定できなかったり、データ分析コンペティションのルールで禁止されていたりなど、本来のデータで埋められないケースは珍しくありません。
欠損値を本来のデータで埋めることが難しい場合、欠損値に対処することが求められます。先にも述べたように、欠損値の正しい対処はデータセットや欠損値にも影響されるため、絶対に正しい対処法というのは存在しません。また、数学的に欠損値を補完すれば、どうしても誤差が発生してしまいます。これらを理解した上で基本的な対処法について見ていきましょう。
欠損値をそのまま扱う
機械学習のモデルによっては欠損値をそのまま扱うこともできます。当然、欠損値が存在したままでは使用できないモデルも存在するため、注意が必要です。欠損値をそのまま扱えるモデルの代表例としてはLightGBMなどがあります。データに対しての理解を疎かにして適当に値を埋めるよりも、欠損値のまま扱った方が精度が高まる場合もあります。LightGBMについてはAIマガジンでもLightGBM 徹底入門 – LightGBMの使い方や仕組み、XGBoostとの違いについてで取り上げています。
欠損値を削除する
欠損値を削除する手法について説明します。欠損値を扱えないモデルを使用する際には初期で検討されやすい手法ですので確実に抑えましょう。
リストワイズ法(List-Wise Deletion)
リストワイズ法は欠損値が含まれているサンプルデータ自体を削除してしまう方法です。欠損値の対処法の中でもイメージがつきやすい方だと思います。欠損値を削除することによって、データセット自体を欠損のない形に変換することができるため、その後モデルなどへの入力が容易になるという利点があります。
MCARでは欠損がランダムに発生しているため、データが歪む事はありません。しかし、欠損値が多いとデータ数自体が減少するため、データ全体がもつ情報量が減少してしまいます。また、MARやMNARでは欠損値の発生自体がランダムではないため、リストワイズ法で削除すると、データが歪む可能性があるため、注意が必要です。

上の表を見ても分かるように欠損値が存在する行が削除されたと思います。理解しやすい手法ですが、この手法は訓練データにのみ使用できることに注意してください。機械学習では主に訓練データ(検証用データ含む)とテストデータの2種類を使用します。訓練用データの削除は「削除したデータは学習に使用しない」と捉えることができます。しかし、テストデータは予測しなければならないデータであるため、削除を行なった場合は「削除したデータは予測できない」ということになります。これは欠損値を持つサンプルに対する予測を放棄することになり、望ましくありません。そのため、リストワイズ法を使用した場合はテストデータをどのように処理するかまでしっかりと検討する必要があります。

ペアワイズ法(Pairwize Deletion)
ペアワイズ法は個々の分析(2変数間の相関)などを行う際に、必要な変数内だけで欠損しているサンプルデータのみを削除する手法です。リストワイズ法のように極端にデータ数が減少する事はなく、削除されるデータ数が必要最低限で済みます。しかし、機械学習の分野においては多変量から予測を行うことがほとんどであることや、変数によって欠損の実装を行わなければならないことから、リストワイズ法の方が比較的よく使われます。
欠損値を補完する
最後に欠損値の補完方法について説明していきます。本稿の中では基本的な概要を抑え、実際の補完に関しては実データやコンペティションなどで経験を積んでいきましょう。
単一代入法(Single Imputation Method)
単一代入法は欠損値1つに対して1つの値で補完する手法です。実際には単一代入法にも複数の種類が存在します。最も初歩的なものは欠損値を同じ変数のその他の数値の平均値で補完する手法です。他にも多変数から回帰モデルを用いて欠損値を予測する回帰代入法なども存在します。単一代入法はデータ数を削減することもありません。実装も比較的簡単なため、データセットに合わせながら多変数のグループごとの平均を代入するなどの工夫を行う場合が多いです。
しかし、単一代入法を使用しても、欠損値を正しく埋められない場合も存在します。リストワイズ法であれば、欠損部分のサンプルデータは削除されるため、残ったデータは最初から存在したものだけになります。しかし、単一代入法では少なからず誤差のあるデータを代入することになるため、相関が異なったりするケースがあるので注意が必要です。
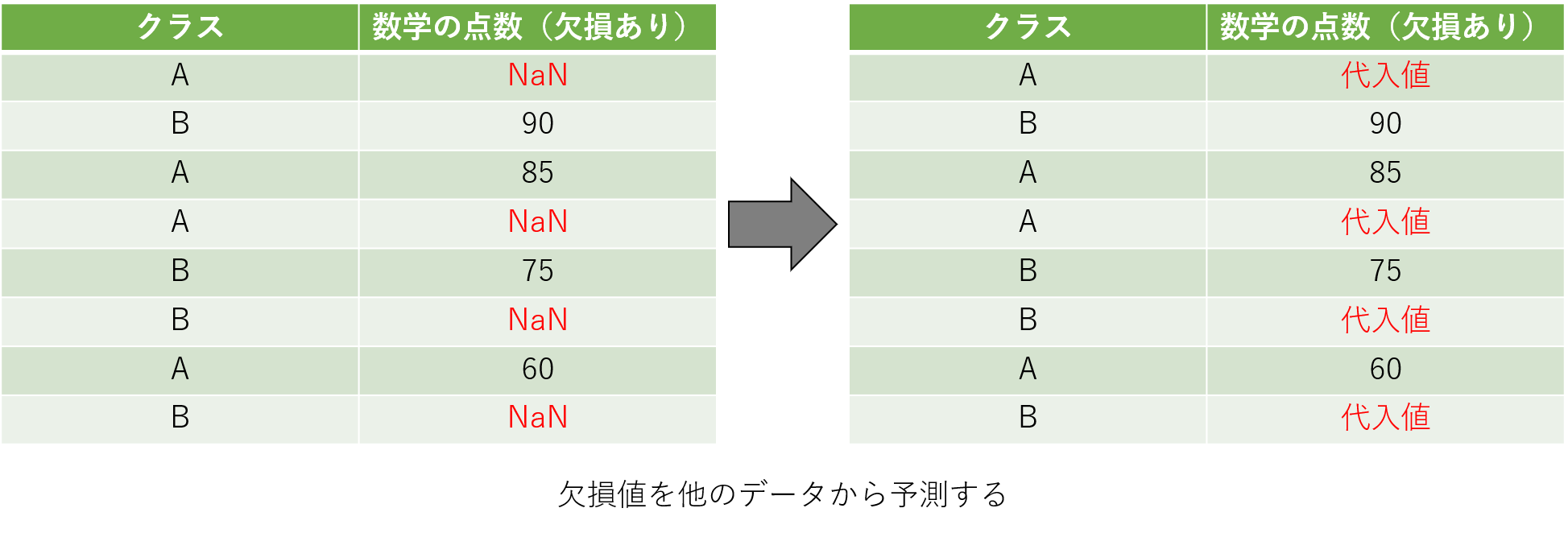
多重代入法(Multiple Imputation Method)
多重代入法は欠損値を代入したデータを複数個用意し、それぞれのデータに対して分析を行い、最終的にそれらの結果を統合して欠損値を補完する手法です。統計学的にはMCARやMARに対しては有効的な手法として用いられています。単一代入法では1つの値を代入した際のデータの歪みを考慮できないというデメリットがあります。多重代入法では欠損値処理の不安定さも結果に含みます。多重代入法のPythonによる実装は現在sickit-learnが実験的に提供しています。参考にしてみてください。(参考:sklearn.impute.IterativeImputer)
完全情報最尤推定法(Full Maximum Likelihood Method; FIML)
完全情報最尤推定法は欠損によって尤度関数を個別に定義し、こちらもMCARやMARに対して有効的な手法として用いられています。全体の尤度を最大化するものです。しかし、最尤推定を理解しながらPythonでの実装を行う事は初学者にとっては難易度が高いため、本稿では紹介のみにとどめたいと思います。
ここまで、欠損値の種類や欠損値処理を説明してきましたが、本稿での内容をより詳細に、数学的に理解されたい方は以下の記事を参考にしてみてください。数学的な基礎知識は機械学習を勉強する上で重要な要素です。(参考:欠損データ分析 (missing data analysis)-完全情報最尤推定法と多重代入法-村山 航)
本稿の後半では主に単一代入法に焦点を当てて欠損値処理を実装していきます。単一代入法の手法は参照できる記事も多く、実装方法も容易なため、比較的取り組みやすいです。データセットにもよりますが、初学者の方は単一代入法とリストワイズ手法を上手く組み合わせながら欠損値を処理できるようにすることをオススメします。(参考:代入法 (統計学))
欠損値処理の実装
本節では、欠損値処理をGoogle Colabを用いて実装していきます。本稿は2021年5月時点でコードの実行確認を行いましたので、Google Colabのデフォルトのバージョンが変更されない限り、ライブラリをそのままインポートすれば同じように実装可能です。是非、ご自身でも実装してみてください。(参考:Google Colabの知っておくべき使い方 – Google Colaboratoryのメリット・デメリットや基本操作のまとめ)
まずは必要なライブラリをインポートしていきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#[IN]: #ライブラリの読み込み import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score import copy import warnings warnings.filterwarnings('ignore') |
データセットにはkaggleのチュートリアルで最も有名なTitanicのデータセットを利用します。こちらのサイトからデータセットをダウンロードしてGoogle Colab上にフォルダにtrain.csvをアップロードして下さい。アップロードが完了したらデータセットを読み込んで、表示します。
titanicの特徴量の説明は以下の通りです。AIマガジンでも以前に特徴量の作成からsubmitまで行なった【Kaggle初心者入門編】タイタニック号で生き残るのは誰?を掲載しています。今回はsubmitまでは行わないため、興味がある方はこちらも確認してみてください。
- PassengerId – 乗客識別ユニークID
- Survived – 生存フラグ(0=死亡、1=生存)
- Pclass – チケットクラス
- Name – 乗客の名前
- Sex – 性別(male=男性、female=女性)
- Age – 年齢
- SibSp – タイタニックに同乗している兄弟/配偶者の数
- parch – タイタニックに同乗している親/子供の数
- ticket – チケット番号
- fare – 料金
- cabin – 客室番号
- Embarked – 出港地(タイタニックへ乗った港)
|
1 2 3 4 5 6 7 |
#[IN]: #titanicデータセットを読み込んで、一部を表示 df = pd.read_csv('train.csv') df.head() |

データセットの最初5行が表示されました。それぞれの特徴量の欠損値の数を確認してみましょう。
|
1 2 3 4 5 6 |
#[IN]: #欠損値の数を表示 print(df.isnull().sum()) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#[OUT]: PassengerId 0 Survived 0 Pclass 0 Name 0 Sex 0 Age 177 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 687 Embarked 2 dtype: int64 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#[IN]: #PassengerID、Name、Ticket以外を抽出する df = df[["Survived","Pclass","Sex","Age","SibSp","Parch","Fare","Cabin","Embarked"]] #Sexで男性を1、女性を0に置換する df["Sex"][df["Sex"] == "male"] = 0 df["Sex"][df["Sex"] == "female"] = 1 #Embarkedの欠損値をSで補完する df["Embarked"] = df["Embarked"].fillna("S") #EmbarkedをSを0、Cを1、Qを2に置換する df["Embarked"][df["Embarked"] == "S" ] = 0 df["Embarked"][df["Embarked"] == "C" ] = 1 df["Embarked"][df["Embarked"] == "Q" ] = 2 |
|
1 2 3 4 5 6 7 8 9 |
#[IN]: #trainとtestに6:4の割合で分割してデータの長さを表示する train,test=train_test_split(df,test_size=0.4,random_state=0) print("訓練用のデータは"+str(len(train))+"です") print("検証用のデータは"+str(len(test))+"です") |
|
1 2 3 4 5 6 |
#[OUT]: 訓練用のデータは534です 検証用のデータは357です |
|
1 2 3 4 5 6 7 |
#[IN]: #欠損値の数を表示 print(train.isnull().sum()) print(test.isnull().sum()) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
#[OUT]: Survived 0 Pclass 0 Sex 0 Age 103 SibSp 0 Parch 0 Fare 0 Cabin 407 Embarked 0 dtype: int64 Survived 0 Pclass 0 Sex 0 Age 74 SibSp 0 Parch 0 Fare 0 Cabin 280 Embarked 0 dtype: int64 |
リストワイズ法による欠損値削除
まずは、「欠損値を処理するよりも削除する方が楽」という考えの元、リストワイズ法を試してみます。pandasのdropnaメソッドを使用して、訓練用データ内の欠損がある行を全て削除します。欠損値処理ごとの精度を比較したいため、copyメソッドを使用して複製を行います。
|
1 2 3 4 5 6 7 8 |
#[IN]: #訓練用データ内の欠損がある行を全て削除して表示する train_drop=train.copy() train_drop=train_drop.dropna() len(train_drop) |
|
1 2 3 4 5 |
#[OUT]: 117 |
訓練用データ数が117になりました。もともとは534であったため、大部分のデータが削除されてしまったことが分かります。検証用データには357ものデータ数が存在しているので、今回の訓練用データの方が検証用データよりも少なくなっています。加えて検証用データの欠損値をどのように処理するかを考えなければなりません。先にも述べたようにテスト用データ(今回の検証用データ)は削除することができません。そのため、欠損値を扱えるモデルを使用するなどして対応する必要があります。数行であれば比較的影響を少なく抑えることができますが、今回はあまりに削除したデータが多いため、リストワイズのみを使用した欠損値処理はここまでにします。
titanicのデータセットの「Cabin」は欠損値が多いのに加えて、カテゴリカルデータであるため、とても扱いづらいです。そこで、「Cabin」を削除し、「Age」の欠損値処理を中心に行っていきたいと思います。このようにあまりに欠損値が多い特徴量に関しては特徴量から外すという選択肢を取ることもあります。
|
1 2 3 4 5 6 7 8 9 |
#[IN]: #訓練用データと検証用データからCabinの列を削除して先頭を表示する train=train.drop("Cabin",axis=1) test=test.drop("Cabin",axis=1) print(train.head()) print(test.head()) |
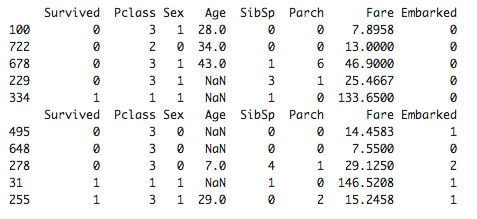
訓練用データ、検証用データから共に「Cabin」を削除することができました。次からは単一代入法を使用して欠損値を補完していきます。
平均値による補完
「平均値で欠損値を補完すれば精度が少しは上がる」という予測のもと、「Age」をまずは平均値で補完していきます。
|
1 2 3 4 5 6 7 8 9 10 11 |
#[IN]: #訓練用データと検証用データのAgeを平均値で補完する train_mean=train.copy() train_mean["Age"] = train_mean["Age"].fillna(train_mean["Age"].mean()) test_mean=test.copy() test_mean["Age"] = test_mean["Age"].fillna(test_mean["Age"].mean()) print(train_mean.isnull().sum()) print(test_mean.isnull().sum()) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
#[OUT]: Survived 0 Pclass 0 Sex 0 Age 0 SibSp 0 Parch 0 Fare 0 Embarked 0 dtype: int64 Survived 0 Pclass 0 Sex 0 Age 0 SibSp 0 Parch 0 Fare 0 Embarked 0 dtype: int64 |
欠損値が補完できていることが確認できています。予測のための準備が整ったので、実際にモデルを構築していきます。今回、モデルはロジスティック回帰を使用します。複数回使用するため、関数で定義し、返り値には検証用データに対する予測値と正解のラベルを設定します。
(ロジスティック回帰の詳細はcodexaの実践 ロジスティック回帰をご参考ください。)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
#[IN]: #ロジスティック回帰をインポートする from sklearn.linear_model import LogisticRegression def get_logi(train,test): #訓練用データから目的変数と説明変数に分割する y_train = train["Survived"].values x_train = train.drop('Survived', axis=1).values #検証用データから目的変数と説明変数に分割する y_test = test["Survived"].values x_test = test.drop('Survived', axis=1).values #ロジスティック回帰 my_logi = LogisticRegression(random_state=0) my_logi = my_logi.fit(x_train, y_train) #検証用データで予測を求める my_prediction = my_logi.predict(x_test) return my_prediction,y_test |
関数が定義できたので、訓練データと検証用データを与えていきます。その後、返り値を利用して精度を求めます。精度にはscikit-learnのaccuracy_score()を用います。
|
1 2 3 4 5 6 7 |
#[IN]: #学習、予測、精度を求める my_prediction_a,test_target_a = get_logi(train_mean,test_mean) accuracy_score(test_target_a, my_prediction_a) |
|
1 2 3 4 5 |
#[OUT]: 0.7927170868347339 |
精度は約0.79になりました。今は通常の平均値を利用して欠損値を補完しましたが、もう少し詳しくデータを眺めて補完方法を考えてみましょう。
PclassごとのAgeの平均値補完
少しAgeについてデータを見ながら考えて見ましょう。どのデータ分析でも変数同士の関連性はとても重要です。まずは訓練用データ内の相関を見てみましょう。
|
1 2 3 4 5 6 |
#[IN]: #訓練用データの相関を表示する train.corr() |
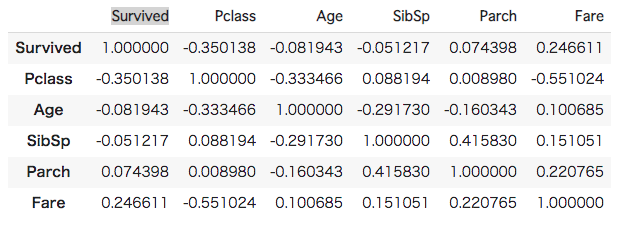
表をみてみると「Pclass」が「Age」と最も相関がありそうです。そのため、Pclassに対するその他変数の平均を調べてみます。ちなみにPclassの説明は以下の通りになります。
* 1 = 上層クラス(お金持ち)
* 2 = 中級クラス(一般階級)
* 3 = 下層クラス(労働階級)
|
1 2 3 4 5 6 |
#[IN]: #Pclassごとの平均を表示する train.groupby('Pclass').mean() |
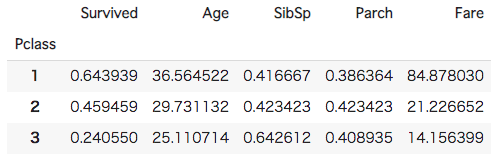
Pclassごとの平均をみてみるとランクが上がるに連れてAgeの平均が上がっています。そのため、「お金持ちの方が年齢が高い傾向にあるのではないか」という予測のもと、「Age」の欠損値を「Pclass」ごとの平均値で補完してみます。そして先程作成したget_logi()関数を使用して予測値を求め、精度を表示します。
|
1 2 3 4 5 6 7 8 9 |
#[IN]: #訓練用データと検証用データをPclassごとの平均値で補完する train_Pclass_mean=train.copy() train_Pclass_mean["Age"]= train_Pclass_mean.groupby('Pclass').transform(lambda x: x.fillna(x.mean()))['Age'] test_Pclass_mean=test.copy() test_Pclass_mean["Age"]= test_Pclass_mean.groupby('Pclass').transform(lambda x: x.fillna(x.mean()))['Age'] |
|
1 2 3 4 5 6 7 |
#[IN]: #学習、予測、精度を求める my_prediction_b,test_target_b=get_logi(train_Pclass_mean,test_Pclass_mean) accuracy_score(test_target_b, my_prediction_b) |
|
1 2 3 4 5 |
#[OUT]: 0.803921568627451 |
こちらも精度は約0.8になりました。通常の平均値と比べてもあまり精度はさほど変わりませんでした。
欠損値を予測して補完する
最後に「Age自体を予測すれば精度が上がるのでは」という予測のもと、欠損値自体を予測したいと思います。
|
1 2 3 4 5 6 7 |
#[IN]: #訓練データと検証用データを複製する train_age_predict=train.copy() test_age_predict=test.copy() |
ランダムフォレストによる実装を行うための関数を定義します。返り値には予測された欠損値が代入された訓練用データと検証用データが設定されています。欠損値の処理を完了した値をそのままget_logi()関数に入力し、予測値を求め、精度を用事します。
ランダムフォレストに関してはcodexaの決定木とランダムフォレストの方でも提供していますのでより詳しく勉強されたい方は参照してみてください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#[IN]: #ランダムフォレストをインポートする from sklearn.ensemble import RandomForestRegressor def age_predict(train,test): #訓練用データをAgeの欠損で分ける x_train = train.dropna() y_train = train[train.isnull().any(axis=1)] #検証用データをAgeの欠損で分ける x_test = test.dropna() y_test = test[test.isnull().any(axis=1)] #欠損がないデータを使用してランダムフォレストを学習する model_train = RandomForestRegressor(random_state=1).fit(x_train.drop(["Age","Survived"],axis=1), x_train["Age"]) model_test = RandomForestRegressor(random_state=1).fit(x_test.drop(["Age","Survived"],axis=1), x_test["Age"]) #Ageの欠損値を予測して補完する y_train["Age"] = model_train.predict(y_train.drop(["Age","Survived"],axis=1)) y_test["Age"] = model_test.predict(y_test.drop(["Age","Survived"],axis=1)) #結合し直す train = pd.concat([x_train,y_train]).sort_index() test = pd.concat([x_test,y_test]).sort_index() return train, test |
|
1 2 3 4 5 6 7 8 9 10 |
#[IN]: #Ageの欠損値を予測する train_age_predict,test_age_predict = age_predict(train_age_predict,test_age_predict) #学習、予測、精度を求める my_prediction_c,test_target_c = get_logi(train_age_predict,test_age_predict) accuracy_score(test_target_c, my_prediction_c) |
|
1 2 3 4 5 |
#[OUT]: 0.8067226890756303 |
| 平均値補完 | 0.7927170868347339 |
| Pclassごとの平均値補完 | 0.803921568627451 |
| ランダムフォレスト補完 | 0.8067226890756303 |
精度は約0.8になりました。他2つの精度と比較しても大きな変化はありませんでした。「Age」の欠損値に対して3つの手法を適応して補完してきましたが、精度に大きな影響を与えることはできませんでした。「Age」という変数自体が「Survived」との相関があまり高くないことも影響していると考えられます。今回は、欠損値の補完方法を説明するのが目的だったため、精度にはこだわりませんでしたが、みなさんは自身が分析するデータセットに合わせた欠損値処理を行い精度向上を目指してみてください。
データ分析を進めていく上で、欠損値との付き合い方は非常に重要になります。色々なデータセットにチャレンジしながら、欠損値の処理を練習してみて下さい。AIマガジンでも【24個掲載】機械学習で使えるデータセット一挙勢揃い!でデータセットを紹介しています。
まとめ
ここまで欠損値に対しての解説と実装を行ってきました。冒頭にも述べたように欠損値はデータセットによって処理方法が異なります。今回紹介した欠損値処理の方法は多くのデータセットで用いやすい汎用的な物を選びました。本稿で取り上げた手法が、皆様が欠損値処理を行うときに少しでも参考になれば幸いです。
codexaでは初学者や独学者向けの機械学習のコースを提供しています。今回のような統計的な内容から、ライブラリまで様々なコースを取り上げています。
・Numpy 入門(無料)
・Pandas 入門(無料)
・Matplotlib 入門(無料)
・線形代数(無料)
・統計基礎(無料)
また、すでに機械学習の基礎知識がある方に向けて、機械学習の様々な手法を詳しく解説したチュートリアルも公開しています。
・実践 線形回帰
・実践 ロジスティック回帰
・決定木とランダムフォレスト
・サポートベクターマシン
・ナイーブベイズ(単純ベイズ分類器)
・XGBoost
・はじめての画像認識
皆様の受講をお待ちしております。

