
機械学習には数多くのライブラリが存在します。例えば数値計算処理を効率的に行ってくれる「Numpy」や、データ解析の手助けをしてくれる「Pandas」などです。
また多くの方が利用している「Scikit-learn」や「TensorFlow」なども機械学習の現場では頻繁に活用されるライブラリの一つです。本記事では機械学習のライブラリとしては比較的新しく、2016年にリリースされた「PyTorch(読み:パイトーチ)」をご紹介します。
機械学習に携わっている方であれば「PyTorch」を一度は耳にしたことがある方も多いかと思います。本記事ではエンジニア向けの「PyTorchで知っておくべき6の基礎知識」をまとめました。PyTorchの基本的な概念やインストール方法、さらに簡単なサンプルコードを掲載しています。
TensorFlowやKerasと肩を並べて人気急上昇のPyTorchの基礎を身につけましょう。
PyTorchとは?
![]()
PyTorchとはPython向けのオープンソース機械学習ライブラリで、Facebookの人工知能研究グループにより初期開発されました。冒頭でも触れましたが、PyTorchは2016年後半に発表された比較的新しいライブラリです。現時点の最新の安定稼働バージョンは「0.4.1」となっており、現段階ではベータバージョンとしての位置付けとなります。
PyTorchの原型は「Torch(読み:トーチ)」と呼ばれる機械学習ライブラリです。Googleに買収されたDeepMind社もTensorFlow以前はTorchを利用していたと言われています。Torchは「Lua言語」で書かれていましたが、Pythonのサポートを行ったのがPyTorchです。
2018年10月前半に待望の「PyTorch 1.0」の開発者向けプレビュー版がリリースされました。PyTorch 1.0のゴールはONNX(Open Neural Network Exchange)とCaffe2、さらにPyTorchの3つの良い部分を一つにまとめることにあります。
多くのエンジニアが期待しているPyTorch 1.0ですが、現在はプレビュー版です。本記事では安定稼働バージョンのPyTorch 0.4を扱います。
PyTorchの人気
他の機械学習ライブラリ/フレームワークと比較してもPyTorchは後発組です。それにも関わらず初期リリースされた2016年から人気を着実に伸ばしています。下のグラフは「アメリカ」の主要な機械学習ライブラリの人気の動向を示したグラフです。データはGoogleトレンドから取得しました。
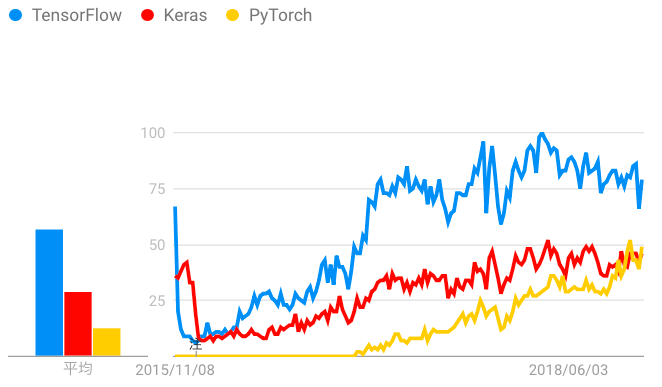
Google主導で開発しているTensorFlowは古くから機械学習分野で活用されるライブラリです。注目をすべき点は2016年から現れたPyTorch(黄色線)です。ここ直近でのGoogleトレンドが示す人気度はKerasと肩を並べる程度まで急成長しているのがわかります。
上記のグラフはアメリカが対象でした。では、日本ではどのような人気なのか調べてみました。上記の3つのライブラリに加え、日本発の「Chainer」もグラフに追加しました。
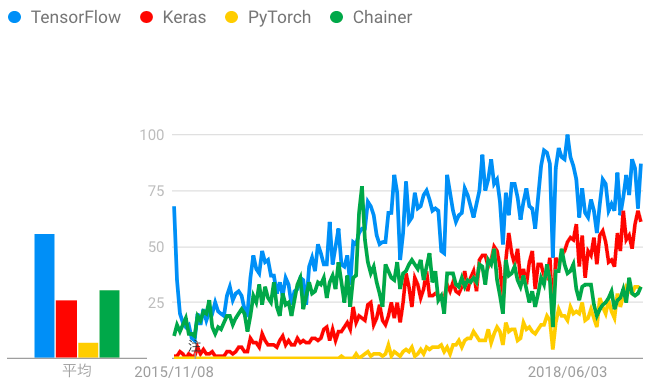
少し煩雑なグラフになりましたが、注目すべきはやはりPyTorch(黄色線)です。日本ではTensorFlowとChainerが人気の高いライブラリでしたが、直近ではPyTorchがChainerと同等の人気を示しています。
Googleトレンドのデータが全てではありませんが、PyTorchがこの近年で人気が急上昇しているのがお判りいただけたかと思います。このようにライブラリを比較すると、人気度がライブラリの良し悪しに見えてしまいますが、決してそのようなことはありません。それぞれ、ライブラリには特徴があり、どのライブラリが最も優れているといった比較は意味がありません。
PyTorchの特徴
機械学習ライブラリとして後発のPyTorchですが、なぜ人気が出ているのでしょうか。その理由の答えともなるPyTorchの特徴について3点ほどご紹介したいと思います。
特徴1 Numpyと類似した操作方法
Pythonでの機械学習プロセスで必須とも言えるライブラリ「Numpy」。本記事をご覧のエンジニアの方であれば、多くの方がNumpyの基本的な使い方を知っていると思います。
そんな方に朗報です。PyTorchでの多くの基本的な操作方法はNumpyと酷似しています。普段使っているNumpyと同じような感覚でPyTorchを使うことが可能です。後ほどPyTorchの基本操作コードをご紹介しますが、Numpyと非常に似ているのが判ると思います。
特徴2 海外を中心にコミュニティが活発
Scikit-learnやTensorFlowと並んで、PyTorchのコミュニティは非常に活発なのも特筆すべき点だと筆者は感じています。コミュニティが活発なゆえに、具体的な操作方法や実装する上での細かい部分など、参照可能なリソースが豊富です。残念ながら現時点で日本語でのリソースが豊富とは言えませんが、これから人気と共にリソースも豊富になると思われます。
また、機械学習/人工知能の最先端の研究者もPyTorchを使っているケースが増えています。これはPyTorchが他のライブラリと比較して簡潔に記述が可能な為です。機械学習の最先端の手法や論文が発表されると、その数週間後にはPyTorchでの実装例などがGitHubで公開されることも少なくありません。
PyTorchのコミュニティが活発なゆえに、様々なメリットがあると思います。
特徴3 動的な計算グラフ
PyTorchとTensorFlowを並べた時に最も特徴的に異なる点が「動的な計算グラフ」です。PyTorchもTensorFlowもニューラルネットワークを構築するライブラリですが、計算に必要となる「計算グラフ」という言葉があります。
計算グラフとはニューラルネットワークの「設計書」のようなものです。TensorFlowやKerasなどのライブラリはこの設計書を「静的」に構築してから計算処理を行います。対してPyTorchでは、この設計書(計算グラフ)を「動的」に構築する方法を採用しています。
「動的」「静的」と話をしていますが、どちらが優れているかの話ではありません。「動的」に計算グラフを構築することで、柔軟かつより複雑なネットワークを実装しやすいメリットがあります。ただし、状況に応じては学習速度が落ちてしまう側面もあるのです。
参考までにですが、静的なアプローチを「Define And Run」と呼ばれています。動的なアプローチは計算グラフを即時に実行することから「Define by Run」と呼ばれています。
このPyTorchの特徴ですが、PyTorchが初めてではありません。元々はChainerやDyNetのアプローチでした。PyTorchは多くの設計においてChainerの考え方を引き継いでいるライブラリです。
PyTorchのインストール方法
実際にPyTorchをインストールして使ってみましょう。最も簡単なインストール方法はPyTorchの公式サイトを参照することです。下記のURLをご参照ください。
https://pytorch.org/get-started/locally/
画面半ばの「START LOCALLY(ローカル環境で始める)」をご覧ください。下の図のように、ご自身の環境に応じて選択をしていくとインストールに必要なコマンドが提示されます。

PyTorchはWindows、Mac、Linux上で動作が可能です。Windowsのマシンでは「Anaconda」を利用してインストールされることをお勧め致します。
オンライン環境で試してみたい方はGoogle Colabで動かしてみるのも一つの手段だと思います。Google Colabとは研究者や教育機関へ機械学習の普及を目的としたGoogleの研究プロジェクトの一つです。インターネット上でブラウザから機械学習に必要な環境を利用することが可能です。(参照:Google Colabとは)
Google Colabには機械学習に必要な多くのライブラリが事前に構築されています。TensorFlowやNumpyなどは特別な環境構築は不要です。ただし、PyTorchは事前にインストールされていません。ですので、追加でGoogle Colabへインストールを行う必要があります。
Google Colabでノートブックを立ち上げて、下記のコードを実行してください。PyTorchがGoogle Colabへ追加でインストールされます。
|
1 2 3 4 5 |
# Google ColabへPyTorchをインストール !pip install -U torch torchvision |
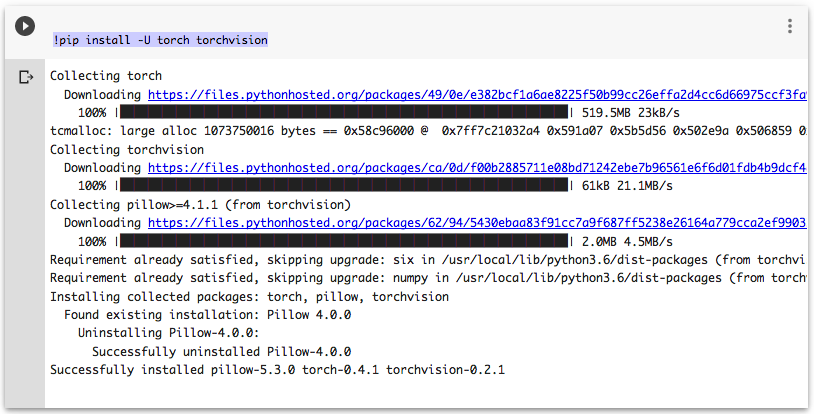
上の図のメッセージが確認できればインストール完了です。
PyTorchの基本操作
それでは実際にPyTorchを使ってみましょう。公式のPyTorchのサイトには多くの初心者向けチュートリアルが公開されています。ドキュメントは英語のみですが、コードを見て学習も可能かと思います。
PyTorchの特徴でも前述しましたが、とてもNumpyに類似しています。Numpyを使ったことがある方であれば、容易に習得が可能かと思います。
1. PyTorchのインポートとバージョンの表示
|
1 2 3 4 5 6 |
# インポート import torch print(torch.__version__) |
|
1 2 3 4 5 |
--出力 0.4.1 |
2. テンソルの作成
テンソルとは多次元配列(multi-dimensional matrix)です。引数で2行2列を指定しています。
|
1 2 3 4 5 6 |
# テンソルの作成 x = torch.Tensor(2, 2) print(x) |
|
1 2 3 4 5 6 |
--出力 tensor([[ 0.0000, 0.0000], [ -35121.8398, -8592028672.0000]]) |
3. テンソルの作成(リスト)
テンソルはPythonのリストからも作成が可能です。
|
1 2 3 4 5 6 |
# リストの作成 list = [[1,2,3],[4,5,6]] list |
|
1 2 3 4 5 |
--出力 [[1, 2, 3], [4, 5, 6]] |
|
1 2 3 4 5 6 |
# テンソルの作成 x2 = torch.Tensor(list) x2 |
|
1 2 3 4 5 6 |
--出力 tensor([[1., 2., 3.], [4., 5., 6.]]) |
4. テンソルのサイズ確認
Numpyでは配列のサイズを shape 属性で確認を行います。PyTorchでは size() のメソッドで確認可能です。
|
1 2 3 4 5 6 7 |
# Numpy配列とサイズの確認 import numpy as np arr = np.array([[1,2,3],[4,5,6]]) arr.shape |
|
1 2 3 4 5 |
--出力 (2, 3) |
|
1 2 3 4 5 |
# PyTorchテンソルのサイズ確認 x2.size() |
|
1 2 3 4 5 |
--出力 torch.Size([2, 3]) |
5. 乱数の生成
機械学習のプロセスでは乱数を生成する機会も多いです。Numpy同様にPyTorchも手軽に乱数生成が行えます。
|
1 2 3 4 5 |
# 一様分布の乱数生成 torch.rand(2,2) |
|
1 2 3 4 5 |
tensor([[0.5512, 0.5853], [0.8480, 0.1157]]) |
|
1 2 3 4 5 |
# 正規分布の乱数生成 torch.randn(2,2) |
|
1 2 3 4 5 6 |
--出力 tensor([[-1.5514, -0.2588], [ 0.6599, -0.8929]]) |
6. 特別な行列の生成
単位行列や空行列の作成も可能です。またNumpyでも頻繁に使われますが、等間隔な数列も作成可能です。
|
1 2 3 4 5 |
# 単位行列の作成 torch.eye(3,3) |
|
1 2 3 4 5 6 7 |
--出力 tensor([[1., 0., 0.], [0., 1., 0.], [0., 0., 1.]]) |
|
1 2 3 4 5 |
# 空のテンソルの作成 torch.empty(4,1) |
|
1 2 3 4 5 6 7 |
tensor([[ 0.0000e+00], [ 1.0842e-19], [-3.5026e+04], [ 1.5849e+29]]) |
|
1 2 3 4 5 |
# 等間隔の数列 torch.linspace(0, 100, 11) |
|
1 2 3 4 |
tensor([ 0., 10., 20., 30., 40., 50., 60., 70., 80., 90., 100.]) |
7. 基本演算
テンソルの足し算、掛け算など基本的な演算をやってみましょう。しつこい様ですがPyTorchの多くのメソッドはNumpyと類似しています。
|
1 2 3 4 5 6 7 8 9 10 |
# テンソルの作成 x = torch.Tensor([[2, 2], [1, 1]]) y = torch.Tensor([[3, 2], [1, 2]]) # 表示 print(x) print(y) |
|
1 2 3 4 5 6 7 8 |
--出力 tensor([[2., 2.], [1., 1.]]) tensor([[3., 2.], [1., 2.]]) |
|
1 2 3 4 5 6 |
# テンソルの足し算 print(x + y) print(torch.add(x, y)) |
|
1 2 3 4 5 6 7 8 |
--出力 tensor([[5., 4.], [2., 3.]]) tensor([[5., 4.], [2., 3.]]) |
|
1 2 3 4 5 6 |
# テンソルのアダマール積(要素の乗法) print(x * y) print(torch.mul(x, y)) |
|
1 2 3 4 5 6 7 8 |
--出力 tensor([[6., 4.], [1., 2.]]) tensor([[6., 4.], [1., 2.]]) |
|
1 2 3 4 5 |
# テンソルの積(ドットプロダクト) print(torch.mm(x, y)) |
|
1 2 3 4 5 6 |
--出力 tensor([[8., 8.], [4., 4.]]) |
|
1 2 3 4 5 |
# テンソルの要素の和 torch.sum(x) |
|
1 2 3 4 5 |
--出力 tensor(6.) |
|
1 2 3 4 5 |
# テンソルの要素の標準偏差 torch.std(x) |
|
1 2 3 4 5 |
--出力 tensor(0.5774) |
|
1 2 3 4 5 |
# テンソルの要素の算術平均 torch.mean(x) |
|
1 2 3 4 5 |
--出力 tensor(1.5000) |
いかがでしたでしょうか?簡単ではありますが、PyTorchの最も基本となる操作方法をご紹介しました。
PyTorchを使って線形回帰
使うデータは「 Ramen Ratings 」を使いましょう。データの利用はkaggleの無料会員登録が必要です。会員登録(またはログイン後)に下記のURLからデータのダウンロードをお願います。
→ https://www.kaggle.com/residentmario/ramen-ratings
ダウンロードしたファイルはZIP形式となります。解凍して「 ramen-ratings.csv 」をJupyter Notebookからアクセスしやすい場所へ格納してください。
PyTorchのコーディング演習として、世界各国で売られているラーメンのレビューデータを使いましょう。ラーメンのブランド、発売国、さらに販売種別(カップラーメン・袋麺)などの特徴量をから評価を予測してみます。
あくまでPyTorchの基礎的な使い方を示すのを目的とします。線形回帰の詳しい解説は行いませんが、興味がある方はcodexaの線形回帰コースのご受講をご検討下さい。
それでは、ノートブックを立ち上げてPyTorchを使ってみましょう。まずは本記事で使うライブラリのインポートを行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# ライブラリのインポート import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # PyTorchのインポート import torch import torch.nn as nn # 評価指標(Scikit-learn) from sklearn.metrics import mean_squared_error |
PyTorchのnnモジュールを「 nn 」としてインポートしています。また、データ処理のためNumpy、Pandas、Matplotlibも加えてインポートしました。
KaggleからダウンロードしたCSVファイルをPandasのデータフレームとして読み込みましょう。
|
1 2 3 4 5 |
# CSVファイルの読み込み ramen = pd.read_csv('ramen-ratings.csv') |
初めて扱うデータですので、簡単なデータ分析を行います。機械学習の一般的なプロセスとして探索的データ解析(EDA)と呼ばれるプロセスがあります。本来であれば時間をかけて、データの特徴や傾向を探りますが、今回は最低限のものに留めます。
|
1 2 3 4 5 |
# データの最初の5行を表示 ramen.head() |
|
1 2 3 4 5 6 7 8 9 10 |
--出力 Review # Brand Variety Style Country Stars Top Ten 0 2580 New Touch T's Restaurant Tantanmen Cup Japan 3.75 NaN 1 2579 Just Way Noodles Spicy Hot Sesame Spicy Hot Sesame Guan... Pack Taiwan 1 NaN 2 2578 Nissin Cup Noodles Chicken Vegetable Cup USA 2.25 NaN 3 2577 Wei Lih GGE Ramen Snack Tomato Flavor Pack Taiwan 2.75 NaN 4 2576 Ching's Secret Singapore Curry Pack India 3.75 NaN |
こちらのデータセットは世界各国で売られているラーメンのレビューデータとなります。それぞれの行がラーメンを示します。では、データのレコード数を確認してみましょう。
|
1 2 3 4 5 |
# データのサイズ確認 ramen.shape |
|
1 2 3 4 5 |
--出力 (2580, 7) |
全部で2580種類のラーメンのレビューがあります。対象がラーメンと考えると、非常に規模のでかい興味深いデータセットですね。Brandはラーメンの販売元、Styleはカップラーメンや袋麺などの種別を表します。またCountryは発売されている国を示します。
|
1 2 3 4 5 |
# ラーメンの国別 ramen['Country'].value_counts()[0:10] |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
--出力 Japan 352 USA 323 South Korea 309 Taiwan 224 Thailand 191 China 169 Malaysia 156 Hong Kong 137 Indonesia 126 Singapore 109 Name: Country, dtype: int64 |
ご覧の通りこちらのデータセットに最も多く含まれるのは日本で販売されているラーメンです。2位がアメリカ、3位は韓国の順です。上位はアメリカを覗くとほとんどアジア圏となりますが、下を確認するとドバイやガーナなど興味深い国も含まれています。
本記事では詳細のデータ解析は行いませんが、各自より深くデータの分岐をしてみて下さい。続いてデータの簡単な前処理を行います。データを確認するとラーメンの評価が「 Unrated (未評価)」のデータが含まれています。こちらのデータは除外しましょう。
|
1 2 3 4 5 6 7 |
# 未評価(Unrated)のラーメンを除外 mask = ramen.index[ramen['Stars'] == 'Unrated'] ramen = ramen.drop(index = mask) ramen.shape |
|
1 2 3 4 5 |
--出力 (2577, 7) |
元は2580件ありましたので、3件のUnratedのデータが除外されました。続いて、ターゲットとなる評価(Stars)のデータ型を、Pythonのオブジェクト型からfloatへ変更しましょう。
|
1 2 3 4 5 6 7 8 9 10 11 |
# Starsのデータ型を確認 print(ramen['Stars'].dtype) # float型へ変換 ramen['Stars'] = ramen['Stars'].astype(float) # 改めてデータ型を確認 print(ramen['Stars'].dtype) |
|
1 2 3 4 5 6 |
--出力 object float64 |
今回、教師データとして使うのは「ブランド(Brand)」「販売種別(Style)」「販売国(Country)」の3つの特徴量です。それ以外は不要ですのでデータから削除を行います
|
1 2 3 4 5 6 |
# 不要なカラムをデータから削除 ramen = ramen.drop(columns=['Review #', 'Top Ten', 'Variety']) ramen.head() |
|
1 2 3 4 5 6 7 8 9 10 |
--出力 Brand Style Country Stars 0 New Touch Cup Japan 3.75 1 Just Way Pack Taiwan 1.00 2 Nissin Cup USA 2.25 3 Wei Lih Pack Taiwan 2.75 4 Ching's Secret Pack India 3.75 |
特徴量として選んだデータですが、全てカテゴリデータとなります。Brand、Style、Countryの3つの特徴量をダミー変数へ変換してあげましょう。ダミー変数とはカテゴリデータのように、もともと数値でないデータに対して0と1を使い表現した変数を指します。詳しくは「ロジスティック回帰 入門コース」をご覧ください。
では、3つの特徴量をダミー変数へ変換しましょう。ダミー変数への変換はPandasの get_dummies() の関数を使うと非常に簡単に行えます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 特徴量のダミー変数化 Country = pd.get_dummies(ramen['Country'], prefix='Country', drop_first=True) Brand = pd.get_dummies(ramen['Brand'], prefix='Brand',drop_first=True) Style = pd.get_dummies(ramen['Style'], prefix='Style',drop_first=True) # ダミー変数化した特徴量を結合 ramendf = pd.concat([Country, Brand,Style], axis=1) # 確認 ramendf.head() |
|
1 2 3 4 5 6 7 8 9 10 |
Country_Bangladesh Country_Brazil Country_Cambodia Country_Canada Country_China Country_Colombia Country_Dubai Country_Estonia Country_Fiji Country_Finland ... Brand_Yum-Mie Brand_Zow Zow Brand_iMee Brand_iNoodle Style_Bowl Style_Box Style_Can Style_Cup Style_Pack Style_Tray 0 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 1 0 2 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 1 0 0 3 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 1 0 4 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 1 0 5 rows × 397 columns |
ご覧通りカテゴリデータだった特徴量がダミー変数(0と1)で表されています。前処理の最後として特徴量(X)とターゲット(y)にデータを切り分けましょう。
|
1 2 3 4 5 6 |
# 特徴量とターゲットへ分割 X = np.array(ramendf, dtype=np.float32) y = np.array(ramen[['Stars']], dtype=np.float32) |
いよいよ本題であるPyTorchの出番です。今回はPyTorchを使って重回帰分析のモデル訓練を行います。すでにPyTorchのNeural Networkモジュール( torch.nn )をインポートしています。線形回帰は nn.Linear() を利用します。
Linear() ですが、第一引数に訓練データの総数を渡します。第二引数は出力するデータのサイズです。|
1 2 3 4 5 |
# 線形回帰モデル model = nn.Linear(397, 1) |
|
1 2 3 4 5 6 7 8 |
# 損失関数 loss = nn.MSELoss() # 最適化関数 optimizer = torch.optim.SGD(model.parameters(), lr=0.6) |
それでは訓練データを使って線形モデルの訓練を始めましょう。訓練を実行するコードですが4つのステップに区切りました。コードのポイントは以下の通りです。コード内のコメントも併せて確認してください。
・反復処理回数(epoch)を1000と設定
・特徴量とターゲットを from_numpy() でNumpy配列からテンソルへ変換を行う
・推測値(outputs)を出力、コスト関数で実際値(targets)と比較してコスト算出
・誤差逆伝播の処理を実行
では、モデル訓練を行ってみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# モデル訓練 for epoch in range(1000): # ステージ1 Numpy配列からテンソルへ変換 inputs = torch.from_numpy(X) targets = torch.from_numpy(y) # ステージ2 推測値を出力して誤差(コスト)を算出 outputs = model(inputs) cost = loss(outputs, targets) # ステージ3 誤差逆伝播(バックプロパゲーション) optimizer.zero_grad() cost.backward() optimizer.step() # ステージ4 50回毎にコストを表示 if (epoch+1) % 100 == 0: print ('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, 1000, cost.item())) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
--出力 Epoch [100/1000], Loss: 0.5760 Epoch [200/1000], Loss: 0.5760 Epoch [300/1000], Loss: 0.5760 Epoch [400/1000], Loss: 0.5760 Epoch [500/1000], Loss: 0.5760 Epoch [600/1000], Loss: 0.5760 Epoch [700/1000], Loss: 0.5760 Epoch [800/1000], Loss: 0.5759 Epoch [900/1000], Loss: 0.5759 Epoch [1000/1000], Loss: 0.5759 |
ご覧通り最初の50回のLoss(コスト)は 0.6180 でしたが、1000回目のコストは 0.5927 と減少してます。訓練済みのモデルに特徴量を入力して推測値を確認してみましょう。
|
1 2 3 4 5 |
# 予測を出力 y_pred = model(torch.from_numpy(X)).data.numpy() |
|
1 2 3 4 5 |
print(y_pred[0:5]) print(y[0:5]) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
--出力 [[4.135929 ] [2.7663915] [3.5037904] [3.4456627] [3.8106773]] [[3.75] [1. ] [2.25] [2.75] [3.75]] |
y_pred がPyTorchを使って構築した線形回帰モデルが出力した推測結果です。対して y がデータの正解ラベル、つまり実際の値となります。回帰モデルの評価方法には様々な方法がありますが、最も初歩的な指標の一つ「平均二乗誤差(MSE)」を算出してみましょう。
|
1 2 3 4 5 |
# 平均二乗誤差を確認 mean_squared_error(y, y_pred) |
|
1 2 3 4 5 |
--出力 0.5759304 |
MSEが0.58となりました。MSEを端的に表すとモデルが推測した値と実際の値の誤差を指標化したものです。MSEは低ければ低いほどモデルの推測精度は「高い」ことを示します。
まとめ
如何でしたでしょうか?本記事では今時のエンジニアが知っておくべきPyTorchの6つの基礎知識をご紹介させて頂きました。
機械学習に携わっている方であれば、それぞれに好みのライブラリがあると思います。本記事の筆者はよほどの理由がない限りはKerasを使うことにしています。
ただし他のライブラリの基本的な使い方を知っておいて損はありません。それぞれのライブラリには得手不得手があり、プロジェクトの成し遂げたい目的やデータの特性に応じて使い分けるべきです。
他にもcodexa(コデクサ)では無料で機械学習関連のライブラリ、基礎統計などのコースを公開しています。機械学習をこれから学ぼうとお考えの方は、是非こちらの無料コースも受講ください!
機械学習 準備編 無料講座以上となります!

